I'm quite new to Julia and i have a .csv File, which is stored inside a gzip, where i want to extract some informations from for educational purposes and to get to know the language better.
In Python there are many helpful functions from Panda to help with that, but i can't seem to get the Problem straight...
This is my Code (I KNOW, VERY WEAK!!!) :
{
import Pkg
#Pkg.add("CSV")
#Pkg.add("DataFrames")
#Pkg.add("CSVFiles")
#Pkg.add("CodecZlib")
#Pkg.add("GZip")
using CSVFiles
using Pkg
using CSV
using DataFrames
using CodecZlib
using GZip
df = CSV.read("Path//to//file//file.csv.gzip", DataFrame)
print(df)
}
I added a Screen to show how the Columns inside the .csv File are looking like.
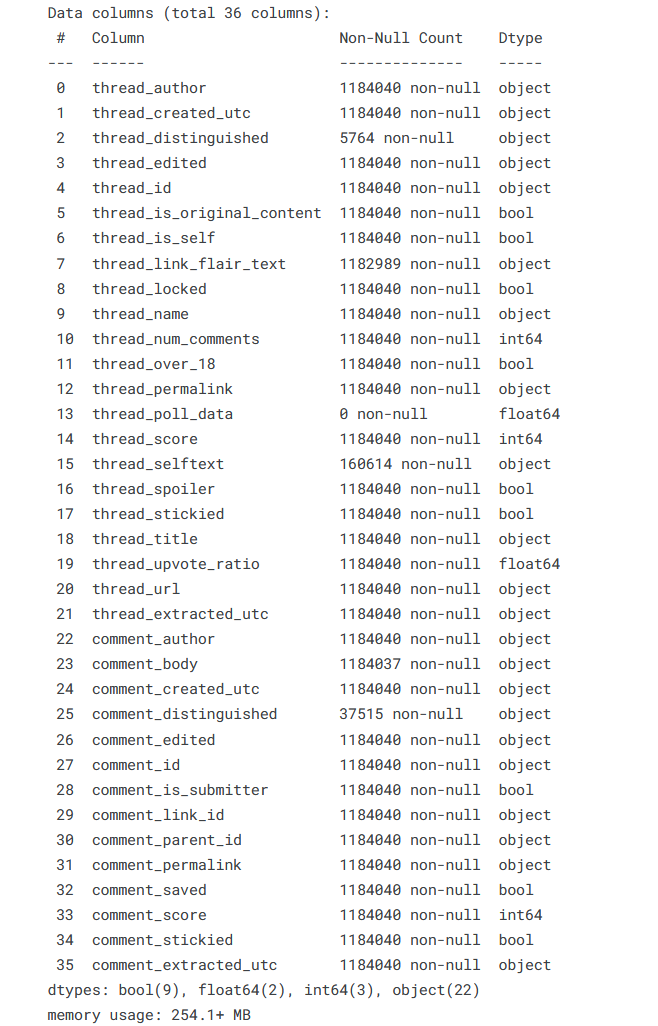 I would like to extract the Dates and make some sort of a Top 10 most commented users, Top 10 days with the most threads etc.
I would like to extract the Dates and make some sort of a Top 10 most commented users, Top 10 days with the most threads etc.
I would like to point out that this is not an Exercise given to me, but a training i would like to do 4 myself.
I know the Panda Version to this is looking like this:
df['threadcreateddate'] = pd.to_datetine(df['thread_created_utc']).dt.date
or
df['commentcreateddate'] = pd.to_datetime(df['comment_created_utc']).dt.date
And to sort it:
pf_number_of_threads = df.groupby('threadcreateddate')["thread_id'].nunique()
If i were to plot it:
df_number_of_threads.plot(kind='line')
plt.show()
To print:
head = df.head()
print(df_number_of_threads.sort_values(ascending=False).head(10))
Can someone help? The df.select() function didn't work for me.
CodePudding user response:
As Sundar R commented it is hard to give you a precise answer for your data as there might be some relevant details. But here is a general pattern you can follow:
julia> using DataFrames
julia> df = DataFrame(id = [1, 1, 2, 2, 2, 3])
6×1 DataFrame
Row │ id
│ Int64
─────┼───────
1 │ 1
2 │ 1
3 │ 2
4 │ 2
5 │ 2
6 │ 3
julia> first(sort(combine(groupby(df, :id), nrow), :nrow, rev=true), 10)
3×2 DataFrame
Row │ id nrow
│ Int64 Int64
─────┼──────────────
1 │ 2 3
2 │ 1 2
3 │ 3 1
What this code does:
groupbygroups data by the column you want to aggregatecombinewithnrowargument counts the number of rows in each group and stores it in:nrowcolumn (this is the default, you could choose other column name)sortsorts data frame by:nrowandrev=truemakes the order descendingfirstpicks 10 first rows from this data frame
If you want something more similar to dplyr in R with piping you can use @chain that is exported by DataFramesMeta.jl:
julia> using DataFramesMeta
julia> @chain df begin
groupby(:id)
combine(nrow)
sort(:nrow, rev=true)
first(10)
end
3×2 DataFrame
Row │ id nrow
│ Int64 Int64
─────┼──────────────
1 │ 2 3
2 │ 1 2
3 │ 3 1
CodePudding user response:
1. Packages
We obviously need DataFrames.jl. And since we're dealing with dates in the data, and doing a plot later, we'll include Dates and Plots as well.
As this example in CSV.jl's documentation shows, no additional packages are needed for gzipped data. CSV.jl can decompress automatically. So, you can remove the other using statements from your list.
julia> using CSV, DataFrames, Dates, Plots
2. Preparing the Data Frame
You can use CSV.read to load the data into the Data Frame, as in the question. Here, I'll use some sample (simplified) data for illustration, with just 4 columns:
julia> df
6×4 DataFrame
Row │ thread_id thread_created_utc comment_id comment_created_utc
│ Int64 String Int64 String
─────┼─────────────────────────────────────────────────────────────────
1 │ 1 2022-08-13T12:00:00 1 2022-08-13T12:00:00
2 │ 1 2022-08-13T12:00:00 2 2022-08-14T12:00:00
3 │ 1 2022-08-13T12:00:00 3 2022-08-15T12:00:00
4 │ 2 2022-08-16T12:00:00 4 2022-08-16T12:00:00
5 │ 2 2022-08-16T12:00:00 5 2022-08-17T12:00:00
6 │ 2 2022-08-16T12:00:00 6 2022-08-18T12:00:00
3. Converting from String to DateTime
To extract the thread dates from the string columns we have, we'll use the Dates standard libary.
Depending on the exact format your dates are in, you might have to add a datefmt argument for conversion to Dates data types (see the Constructors section of Dates in the Julia manual). Here in the sample data, the dates are in ISO standard format, so we don't need to specify the date format explicitly.
In Julia, we can get the date directly without intermediate conversion to a date-time type, but since it's a good idea to have the columns be in the proper type anyway, we'll first convert the existing columns from strings to DateTime:
julia> transform!(df, [:thread_created_utc, :comment_created_utc] .=> ByRow(DateTime), renamecols = false)
6×4 DataFrame
Row │ thread_id thread_created_utc comment_id comment_created_utc
│ Int64 DateTime Int64 DateTime
─────┼─────────────────────────────────────────────────────────────────
1 │ 1 2022-08-13T12:00:00 1 2022-08-13T12:00:00
2 │ 1 2022-08-13T12:00:00 2 2022-08-14T12:00:00
3 │ 1 2022-08-13T12:00:00 3 2022-08-15T12:00:00
4 │ 2 2022-08-16T12:00:00 4 2022-08-16T12:00:00
5 │ 2 2022-08-16T12:00:00 5 2022-08-17T12:00:00
6 │ 2 2022-08-16T12:00:00 6 2022-08-18T12:00:00
Though it looks similar, this data frame doesn't use Strings for the date-time columns, instead has proper DateTime type values.
(For an explanation of how this transform! works, see the DataFrames manual: Selecting and transforming columns.)
4. Creating Date columns
Now, creating the date columns is as easy as:
julia> df.threadcreateddate = Date.(df.thread_created_utc);
julia> df.commentcreateddate = Date.(df.comment_created_utc);
julia> df
6×6 DataFrame
Row │ thread_id thread_created_utc comment_id comment_created_utc commentcreateddate threadcreatedate
│ Int64 DateTime Int64 DateTime Date Date
─────┼───────────────────────────────────────────────────────────────────────────────────────────────────────
1 │ 1 2022-08-13T12:00:00 1 2022-08-13T12:00:00 2022-08-13 2022-08-13
2 │ 1 2022-08-13T12:00:00 2 2022-08-14T12:00:00 2022-08-14 2022-08-13
3 │ 1 2022-08-13T12:00:00 3 2022-08-15T12:00:00 2022-08-15 2022-08-13
4 │ 2 2022-08-16T12:00:00 4 2022-08-16T12:00:00 2022-08-16 2022-08-16
5 │ 2 2022-08-16T12:00:00 5 2022-08-17T12:00:00 2022-08-17 2022-08-16
6 │ 2 2022-08-16T12:00:00 6 2022-08-18T12:00:00 2022-08-18 2022-08-16
These could also be written as a transform! call, and in fact the transform! call in the previous code segment could have instead been replaced with df.thread_created_utc = DateTime.(df.thread_created_utc) and df.comment_created_utc = DateTime.(df.comment_created_utc). However, transform offers a very powerful and flexible syntax that can do a lot more, so it's useful to familiarize yourself with it if you're going to work on DataFrames.
5. Getting the number of threads per day
julia> gdf = combine(groupby(df, :threadcreateddate), :thread_id => length ∘ unique => :number_of_threads)
2×2 DataFrame
Row │ threadcreateddate number_of_threads
│ Date Int64
─────┼──────────────────────────────────────
1 │ 2022-08-13 1
2 │ 2022-08-16 1
Note that df.groupby('threadcreateddate') becomes groupby(df, :threadcreateddate), which is a common pattern in Python-to-Julia conversions. Julia doesn't use the . based object-oriented syntax, and instead the data frame is one of the arguments to the function.
length ∘ unique uses the function composition operator ∘, and the result is a function that applies unique and then length. Here we take the unique values of thread_id column in each group, apply length to them (so, the equivalent of nunique), and store the result in number_of_threads column in a new GroupedDataFrame called gdf.
6. Plotting
julia> plot(gdf.threadcreateddate, gdf.number_of_threads)
Since our grouped data frame conveniently contains both the date and the number of threads, we can plot the number_of_threads against the dates, making for a nice and informative visualization.