I'm fairly new to C# and programming in general and I was trying out parallel programming.
I have written this example code that computes the sum of an array first, using multiple threads, and then, using one thread (the main thread).
I've timed both cases.
static long Sum(int[] numbers, int start, int end)
{
long sum = 0;
for (int i = start; i < end; i )
{
sum = numbers[i];
}
return sum;
}
static async Task Main()
{
// Arrange data.
const int COUNT = 100_000_000;
int[] numbers = new int[COUNT];
Random random = new();
for (int i = 0; i < numbers.Length; i )
{
numbers[i] = random.Next(100);
}
// Split task into multiple parts.
int threadCount = Environment.ProcessorCount;
int taskCount = threadCount - 1;
int taskSize = numbers.Length / taskCount;
var start = DateTime.Now;
// Run individual parts in separate threads.
List<Task<long>> tasks = new();
for (int i = 0; i < taskCount; i )
{
int begin = i * taskSize;
int end = (i == taskCount - 1) ? numbers.Length : (i 1) * taskSize;
tasks.Add(Task.Run(() => Sum(numbers, begin, end)));
}
// Wait for all threads to finish, as we need the result.
var partialSums = await Task.WhenAll(tasks);
long sumAsync = partialSums.Sum();
var durationAsync = (DateTime.Now - start).TotalMilliseconds;
Console.WriteLine($"Async sum: {sumAsync}");
Console.WriteLine($"Async duration: {durationAsync} miliseconds");
// Sequential
start = DateTime.Now;
long sumSync = Sum(numbers, 0, numbers.Length);
var durationSync = (DateTime.Now - start).TotalMilliseconds;
Console.WriteLine($"Sync sum: {sumSync}");
Console.WriteLine($"Sync duration: {durationSync} miliseconds");
var factor = durationSync / durationAsync;
Console.WriteLine($"Factor: {factor:0.00}x");
}
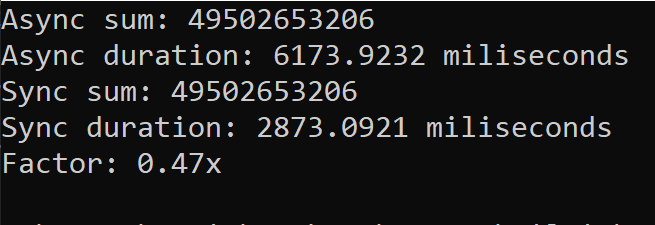
When the array size is 100 million, the parallel sum is computed 2x faster. (on average). But when the array size is 1 billion, it's significantly slower than the sequential sum.
Why is it running slower?
Hardware Information
Environment.ProcessorCount = 4
GC.GetGCMemoryInfo().TotalAvailableMemoryBytes = 8468377600
Timing:
When array size is 100,000,000
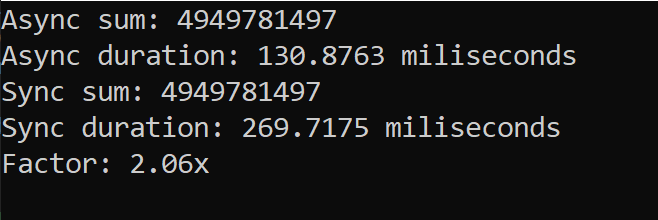
When array size is 1,000,000,000
New Test:
This time instead of separate threads (it was 3 in my case) working on different parts of a single array of 1,000,000,000 integers, I physically divided the dataset into 3 separate arrays of 333,333,333 (one-third in size). This time, although, I'm working on adding up a billion integers on the same machine, my parallel code runs faster (as expected)
private static void InitArray(int[] numbers)
{
Random random = new();
for (int i = 0; i < numbers.Length; i )
{
numbers[i] = (int)random.Next(100);
}
}
public static async Task Main()
{
Stopwatch stopwatch = new();
const int SIZE = 333_333_333; // one third of a billion
List<int[]> listOfArrays = new();
for (int i = 0; i < Environment.ProcessorCount - 1; i )
{
int[] numbers = new int[SIZE];
InitArray(numbers);
listOfArrays.Add(numbers);
}
// Sequential.
stopwatch.Start();
long syncSum = 0;
foreach (var array in listOfArrays)
{
syncSum = Sum(array);
}
stopwatch.Stop();
var sequentialDuration = stopwatch.Elapsed.TotalMilliseconds;
Console.WriteLine($"Sequential sum: {syncSum}");
Console.WriteLine($"Sequential duration: {sequentialDuration} ms");
// Parallel.
stopwatch.Restart();
List<Task<long>> tasks = new();
foreach (var array in listOfArrays)
{
tasks.Add(Task.Run(() => Sum(array)));
}
var partialSums = await Task.WhenAll(tasks);
long parallelSum = partialSums.Sum();
stopwatch.Stop();
var parallelDuration = stopwatch.Elapsed.TotalMilliseconds;
Console.WriteLine($"Parallel sum: {parallelSum}");
Console.WriteLine($"Parallel duration: {parallelDuration} ms");
Console.WriteLine($"Factor: {sequentialDuration / parallelDuration:0.00}x");
}
Timing
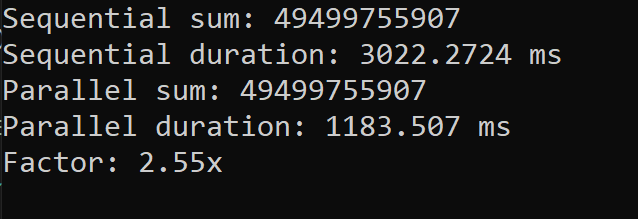
I don't know if it helps figure out what went wrong in the first approach.
CodePudding user response:
The asynchronous pattern is not the same as running code in parallel. The main reason for asynchronous code is better resource utilization while the computer is waiting for some kind of IO device. Your code would be better described as parallel computing or concurrent computing.
While your example should work fine, it may not be the easiest, nor optimal way to do it. The easiest option would probably be to use Parallel Linq: numbers.AsParallel().Sum();. There is also a Parallel.For method that should be better suited, including an overload that maintains a thread local state. Note that while the parallel.For will attempt to optimize its partitioning, you probably want to process chunks of data in each iteration to reduce overhead. I would try around 1-10k values or so.
We can only guess the reason your parallel method is slower. Summing numbers is a really fast operation, so it may be that the computation is limited by memory bandwith or Cache usage. And while you want your work partitions to be fairly large, using too large partitions may result in less overall parallelism if a thread gets suspended for any reason. You may also want partitions on certain sizes to work well with the caching system, see cache associativity. It is also possible you are including things you did not intend to measure, like compilation times or GCs, See benchmark .Net that takes care of many of the edge cases when measuring performance.
Also, never use DateTime for measuring performance, Stopwatch is both much easier to use and much more accurate.
CodePudding user response:
My machine has 4GB RAM, so initializing an int[1_000_000_000] results in memory paging. Going from int[100_000_000] to int[1_000_000_000] results in non-linear performance degradation (100x instead of 10x). Essentially a CPU-bound operation becomes I/O-bound. Instead of adding numbers, the program spends most of its time reading segments of the array from the disk. In these conditions using multiple threads can be detrimental for the overall performance, because the pattern of accessing the storage device becomes more erratic and less streamlined.
Maybe something similar happens on your 8GB RAM machine too, but I can't say for sure.