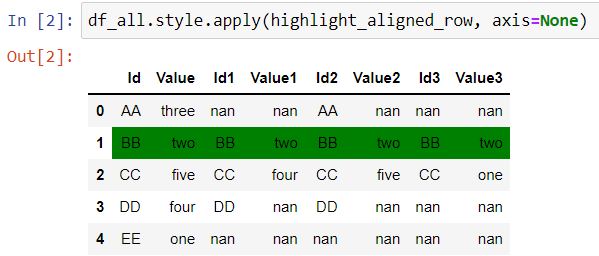
I have a dataframe df (see image below) which I need to merge with N dataframes.
In this post, for the sake of clarity, N=3.
The goal is to check if every value of the column Id exists in the three other dataframes and have the same value as well. And if so, the row has to be highlighted with a green color. That's it !

Code :
import pandas as pd
import numpy as np
### --- Dataframes
df = pd.DataFrame({'Id' : ['AA', 'BB', 'CC', 'DD', 'EE'],
'Value': ['three', 'two', 'five','four', 'one']})
df1 = pd.DataFrame({'Id1' : [np.nan, 'CC', 'BB', 'DD', np.nan],
'Value1' : ['one', 'four', 'two', np.nan, np.nan]})
df2 = pd.DataFrame({'Id2' : ['AA', 'BB', 'CC', 'DD', 'JJ'],
'Value2' : [np.nan, 'two', 'five', np.nan, 'six']})
df3 = pd.DataFrame({'Id3' : ['FF', 'HH', 'CC', 'GG', 'BB'],
'Value3' : ['seven', 'five', 'one','three', 'two']})
### --- Joining df to df1, df2 and df3
df_df1 = df.merge(df1, left_on='Id', right_on='Id1', how='left')
df_df1_df2 = df_df1.merge(df2, left_on='Id', right_on='Id2', how='left')
df_df1_df2_df3 = df_df1_df2.merge(df3, left_on='Id', right_on='Id3', how='left')
### --- Creating a function to highlight the aligned rows
def highlight_aligned_row(x):
m1 = (x['Id'] == x['Id1']) & (x['Id'] == x['Id2']) & (x['Id'] == x['Id3'])
m2 = (x['Value'] == x['Value1']) & (x['Value']== x['Value2']) & (x['Value'] == x['Value3'])
df = pd.DataFrame('background-color: ', index=x.index, columns=x.columns)
df['Id'] = np.where(m1 & m2, f'background-color: green', df['Id'])
return df
>>> df_df1_df2_df3.style.apply(highlight_aligned_row, axis=None)
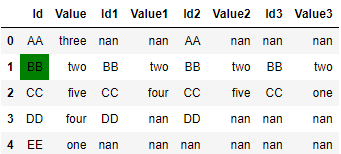
My questions are :
- How do we highlight the entire row when a condition is fulfilled ?
- Is there a more efficient way to merge 10 dataframes ?
- How can we check if every value/row of the original dataframe is aligned with the values of the final dataframe (after the merge) ?
Thank you in advance for your suggestions and your help !
CodePudding user response:
I would do it like this. Hope the comments in between make clear what I am doing. Hopefully, they also answer your questions, but let me know if anything remains unclear.
import pandas as pd
import numpy as np
df = pd.DataFrame({'Id' : ['AA', 'BB', 'CC', 'DD', 'EE'],
'Value': ['three', 'two', 'five','four', 'one']})
df1 = pd.DataFrame({'Id1' : [np.nan, 'BB', 'CC', 'DD', np.nan],
'Value1' : ['one', 'two', 'four', np.nan, np.nan]})
df2 = pd.DataFrame({'Id2' : ['AA', 'BB', 'CC', 'DD', 'JJ'],
'Value2' : [np.nan, 'two', 'five', np.nan, 'six']})
df3 = pd.DataFrame({'Id3' : ['FF', 'BB', 'CC', 'GG', 'HH'],
'Value3' : ['seven', 'two', 'one','v4', 'v5']})
# *IF* your dfs (like above) are all same shape with same index, then easiest is to
# collect your dfs in a list and use pd.concat along axis 1 to merge:
# dfs = [df, df1, df2, df3]
# df_all = pd.concat(dfs, axis=1)
# *BUT* from your comments, this does not appear to be the case. Then instead,
# again collect dfs in a list, and merge them with df in a loop
dfs = [df, df1, df2, df3]
for idx, list_df in enumerate(dfs):
if idx == 0:
df_all = list_df
else:
df_all = df_all.merge(list_df, left_on='Id',
right_on=[col for col in list_df.columns
if col.startswith('Id')][0],
how='left')
def highlight_aligned_row(x):
n1 = x.loc[:,[col for col in x.columns
if col.startswith('Id')]].eq(x.loc[:, 'Id'], axis=0).all(axis=1)
m1 = x.loc[:,[col for col in x.columns
if col.startswith('Value')]].eq(x.loc[:, 'Value'], axis=0).all(axis=1)
eval_bool = n1 & m1
# Just for x['Id']: [False, True, False, False, False]
# repeat 8 times (== len(df.columns)) will lead to .shape == (40,).
# reshape to 5 rows (== len(df)) and 8 cols. Second row will be [8x True] now,
# other rows all 8x False
rows, cols = len(eval_bool), len(x.columns) # 5, 8
eval_bool_repeated = eval_bool.to_numpy().repeat(cols).reshape(rows,cols)
# setup your df
df = pd.DataFrame('background-color: ', index=x.index, columns=x.columns)
# now apply eval_bool_repeated to entire df, not just df['Id']
df = np.where(eval_bool_repeated, f'background-color: green', df)
return df
Result: