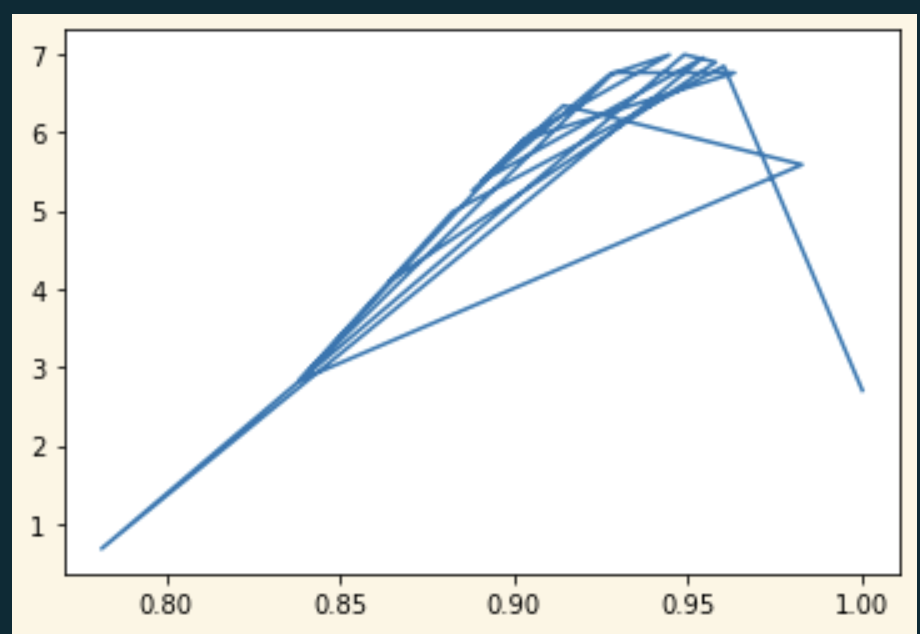
I am trying to fit a beta distribution to some data, and then plot how well the beta distribution fits the data. But the output looks really weird and incorrect.
import scipy.stats as stats
import matplotlib.pyplot as plt
x = np.array([0.9999999 , 0.9602287 , 0.8823198 , 0.83825594, 0.92847216,
0.9632976 , 0.90275735, 0.8383094 , 0.9826664 , 0.9141795 ,
0.88799196, 0.9272752 , 0.94456017, 0.90466917, 0.8905505 ,
0.95424247, 0.781545 , 0.9489085 , 0.9578988 , 0.8644015 ])
beta_params = stats.beta.fit(x)
print(beta_params)
#(3.243900357315478, 1.5909897101396109, 0.7270083219563888, 0.27811444901271615
beta_pdf = stats.beta.pdf(x, beta_params[0], beta_params[1], beta_params[2], beta_params[3])
print(beta_pdf)
#[2.70181543 6.8442073 4.98204632 2.82445508 6.76055614 6.75910611
#5.90419012 2.82696622 5.58521916 6.34096675 5.2508072 6.73212694
#6.98854653 5.98225724 5.36937625 6.9519977 0.67812362 6.99116729
#6.89484982 4.10113147]
plt.plot(x, beta_pdf)
CodePudding user response:
I'm not a statistician, but looking at your code I see that x is unordered.
Does sorting x before fit helps you?
x = np.sort(x)
beta_params = stats.beta.fit(x)
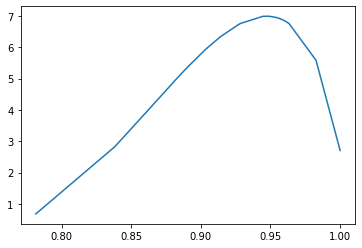
Doing so, you'd get this: