I have a dataframe which looks like the:
import pandas as pd
df_ref = pd.DataFrame({'district':['A Nzo DM','A Nzo DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM'],
'visit_date':['2021-07-31','2021-07-31','2021-07-31','2021-07-31','2021-08-31','2021-08-31','2021-08-31'],
'province':['EC','EC','NC','NC','NC','NC','NC'],
'age_group':['35-49','50-59','18-34','35-49','18-34','35-49','Unidentified'],
'sex':['Male','Female','Female','Male','Female','Male','Female'],
'vaccinations':[1,5,6,8,9,10,14]})
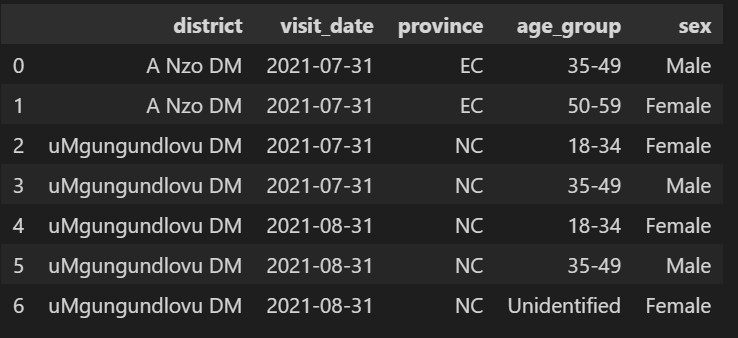 The data is going to be used in data visualization software I need each
The data is going to be used in data visualization software I need each district for each 'visit_date(already sampled to month) to be mapped [![enter image description here][1]][1] whereby eachSex (Male and Female) has these age groups mapped to it (18-34,35-49,50-59,60 ,Unidentified) for each month = (visit_date`).
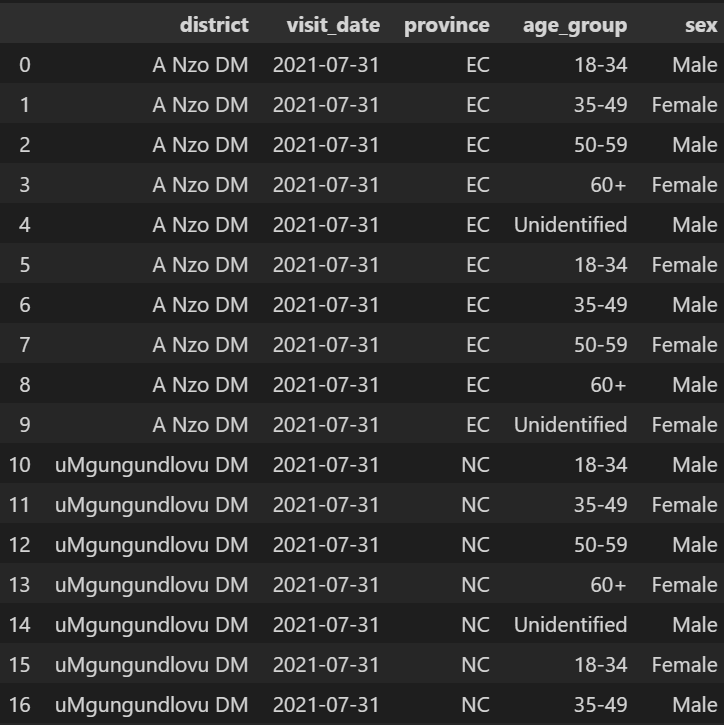
The result would be:
maz = {'district':['A Nzo DM','A Nzo DM','A Nzo DM','A Nzo DM','A Nzo DM',
'A Nzo DM','A Nzo DM','A Nzo DM','A Nzo DM','A Nzo DM',
'uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM',
'uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM',
'uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM',
'uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM','uMgungundlovu DM'],
'visit_date':['2021-07-31','2021-07-31','2021-07-31','2021-07-31','2021-07-31',
'2021-07-31','2021-07-31','2021-07-31','2021-07-31','2021-07-31',
'2021-07-31','2021-07-31','2021-07-31','2021-07-31','2021-07-31',
'2021-07-31','2021-07-31','2021-07-31','2021-07-31','2021-07-31',
'2021-08-31','2021-08-31','2021-08-31','2021-08-31','2021-08-31',
'2021-08-31','2021-08-31','2021-08-31','2021-08-31','2021-08-31'],
'province':['EC','EC','EC','EC','EC',
'EC','EC','EC','EC','EC',
'NC','NC','NC','NC','NC',
'NC','NC','NC','NC','NC',
'NC','NC','NC','NC','NC',
'NC','NC','NC','NC','NC'],
'age_group':['18-34','35-49','50-59','60 ','Unidentified',
'18-34','35-49','50-59','60 ','Unidentified',
'18-34','35-49','50-59','60 ','Unidentified',
'18-34','35-49','50-59','60 ','Unidentified',
'18-34','35-49','50-59','60 ','Unidentified',
'18-34','35-49','50-59','60 ','Unidentified'],
'sex':['Male','Female','Male','Female',
'Male','Female','Male','Female',
'Male','Female','Male','Female',
'Male','Female','Male','Female',
'Male','Female','Male','Female',
'Male','Female','Male','Female',
'Male','Female','Male','Female',
'Male','Female'],}
df_output = pd.DataFrame(maz)
CodePudding user response:
IIUC, you need a product of 'age_group' and 'sex' columns and then a 'cross' merge with rest of the columns and then drop duplicates
t = pd.DataFrame(
itertools.product(df_ref["age_group"], df_ref["sex"]), columns=["age_group", "sex"]
).drop_duplicates(ignore_index=True)
out = pd.merge(
df_ref[["district", "visit_date", "province"]], t, how="cross"
).drop_duplicates(ignore_index=True)
print(out):
Note: This doesn't have 60 because input dataframe doesn't have it.
district visit_date province age_group sex
0 A Nzo DM 2021-07-31 EC 35-49 Male
1 A Nzo DM 2021-07-31 EC 35-49 Female
2 A Nzo DM 2021-07-31 EC 50-59 Male
3 A Nzo DM 2021-07-31 EC 50-59 Female
4 A Nzo DM 2021-07-31 EC 18-34 Male
5 A Nzo DM 2021-07-31 EC 18-34 Female
6 A Nzo DM 2021-07-31 EC Unidentified Male
7 A Nzo DM 2021-07-31 EC Unidentified Female
8 uMgungundlovu DM 2021-07-31 NC 35-49 Male
9 uMgungundlovu DM 2021-07-31 NC 35-49 Female
10 uMgungundlovu DM 2021-07-31 NC 50-59 Male
11 uMgungundlovu DM 2021-07-31 NC 50-59 Female
12 uMgungundlovu DM 2021-07-31 NC 18-34 Male
13 uMgungundlovu DM 2021-07-31 NC 18-34 Female
14 uMgungundlovu DM 2021-07-31 NC Unidentified Male
15 uMgungundlovu DM 2021-07-31 NC Unidentified Female
16 uMgungundlovu DM 2021-08-31 NC 35-49 Male
17 uMgungundlovu DM 2021-08-31 NC 35-49 Female
18 uMgungundlovu DM 2021-08-31 NC 50-59 Male
19 uMgungundlovu DM 2021-08-31 NC 50-59 Female
20 uMgungundlovu DM 2021-08-31 NC 18-34 Male
21 uMgungundlovu DM 2021-08-31 NC 18-34 Female
22 uMgungundlovu DM 2021-08-31 NC Unidentified Male
23 uMgungundlovu DM 2021-08-31 NC Unidentified Female