Im looking to mark key points in cycles based on certain conditions.
Here is the result I am looking for:
import pandas as pd
import numpy as np
Data3 = {'Cycle': ['1', '1', '1', '1', '1', '1', '2','2', '2', '2', '2', '2'],
'Value': [20, 24, 25, 18,15,12,1,2,19,18,12,1],
'Diff2':[1,10,18,-12,-50,-14,14,150,130,-140,12,14],
'POI':['-','-','A','-','B','-','-','-','A','B','-','-']}
df = pd.DataFrame(Data3)
Based off another answer I understand I need to use groupby and have come up with something like this:
Data3['POI'] = np.select([Data3['Value'].eq(POI.transform('max')),
Data3['Diff2'].eq(POI.transform('min'))]
['A','B'])
I need to mark A and B for each cycle, as shown in the Data frame above.
To get A: A is simply the max in the "Value" column
To get B: B is the minimum number in the Diff2 column
Im not sure how to use the groupby for multiple columns, so any help would be great.
Data3 = {'Cycle': ['1', '1', '1', '1', '1', '1', '2','2', '2', '2', '2', '2'],
'Value': [20, 24, 25, 18,15,12,1,2,19,18,12,1],
'Diff2':[1,10,18,-12,-50,-14,14,150,130,-140,12,14],
}
df = pd.DataFrame(Data3)
df['POI'] = Data3.groupby('Cycle').apply(
lambda g: np.select([g['Value'] == g['Value'].max(),
g['Diff2'] == g['Diff2'].min()], ['A', 'B'], default='-')
).explode().set_axis(df.index, axis=0)
CodePudding user response:
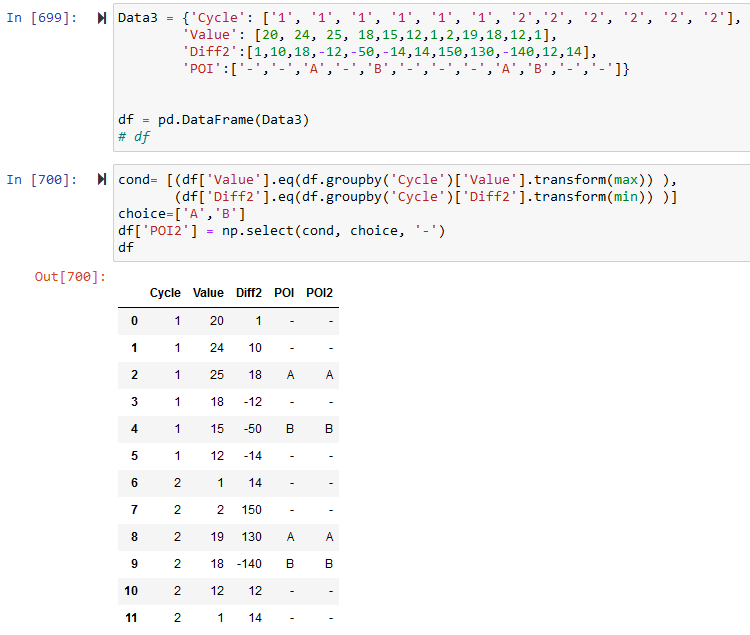
here is one way to do it. i created POI2, to have a comparison with the expected output
cond= [(df['Value'].eq(df.groupby('Cycle')['Value'].transform(max)) ),
(df['Diff2'].eq(df.groupby('Cycle')['Diff2'].transform(min)) )]
choice=['A','B']
df['POI2'] = np.select(cond, choice, '-')
df
Cycle Value Diff2 POI POI2
0 1 20 1 - -
1 1 24 10 - -
2 1 25 18 A A
3 1 18 -12 - -
4 1 15 -50 B B
5 1 12 -14 - -
6 2 1 14 - -
7 2 2 150 - -
8 2 19 130 A A
9 2 18 -140 B B
10 2 12 12 - -
11 2 1 14 - -
Screenshot
CodePudding user response:
df['POI'] = df.groupby('Cycle').apply(
lambda g: np.select([g['Value'] == g['Value'].max(),
g['Diff2'] == g['Diff2'].min()], ['A', 'B'], default='-')
).explode().set_axis(df.index, axis=0)