I need help understanding and implementing K-Fold cross validation.
As far as I understand cross validation, it is used to divide the dataset into k subgroups, to have a greater variation in the training and test data.
So my first question is: does it replace an ordinary train_test_split(), or is it used as an addition, when I want to save and reuse the model?
When I create a model like this:
X = df["A"]
y = df["B"]
model = LinearRegression()
kfold = KFold(shuffle=True, n_splits=10)
scores = cross_val_score(model, X, y, cv=kfold)
And I save it to reuse it on real data, I get the error that the model has no predict-method and has not been fitted yet. If I just call model.fit(X, y) in the end, the scores don‘t get considered, do they?
How do I correctly fit the model using cross validation, so I can save and use it afterwards?
CodePudding user response:
To your first question:
It is an alternative method. You can think of it as doing a train_test_split 10 times on the dataset with no overlap in the test data. What you get is a more valid score because you use the model on the whole dataset.
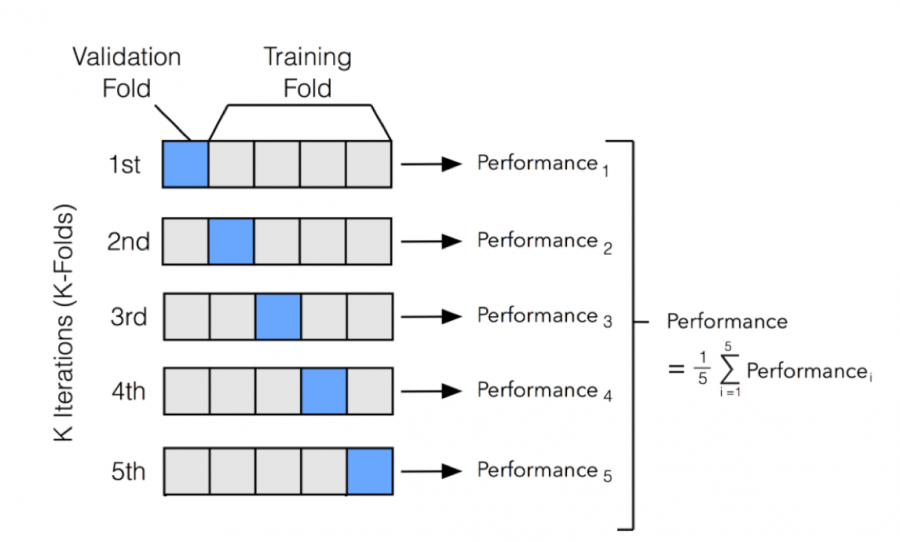
To your second question:
You just need to fit the model. You either define a training set (by train_test_split) and fit it on that and use cv for evaluation , use the whole training set, or the most sophisticated: you loop over your folds, and fit a seperate model for each training set. For the final prediction you average over your models.
kf = KFold(n_splits=10)
for fold,(train_ids, valid_ids) in enumerate(kf.split(
df)):
Xtrain = df.loc[train_ids,'A']
ytrain = df.loc[train_ids,'B']
Xvalid = df.loc[valid_ids,'A']
yvalid = df.loc[valid_ids,'B']
model.fit(Xtrain, ytrain)
model.score(Xvalid, yvalid)
model.save_model(..)
Then you can either use the best performing or as mentioned above use all 10 models and averaging the predictions.
CodePudding user response:
You can't. It doesn't really make sense in that context. In your code, there are actually 10 individual models, and if you shuffle the models themselves will change. The cross_val_score is essentially for you to evaluate whether or not your features and model types work well for your problem.
You need a separate fit step in order to use it downstream.
CodePudding user response:
I think you may want to train/test your model first. Then utilize k fold to further validate your model based on splitting your sample set.
The two concepts are separate.