Not quite sure how to describe what I'm looking for, so hopefully an example will help.
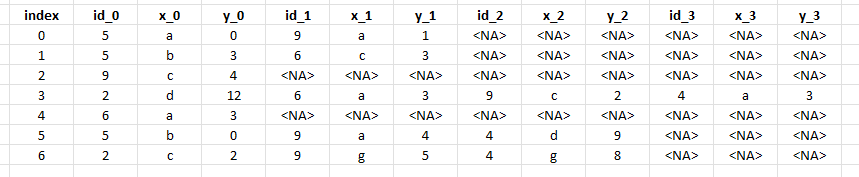
- Each row contains up to n sets of observations (here, n=4)
- The observations are grouped by (id, x, y)
- The id represents some sort of unique location and the x, y are related values
So, for example, in the first row (index=0), there are two observations, at id=5 (x=a, y=0) and at id=9 (x=a, y=1)
I want to reshape / pivot the data such that there is a column for every location with the corresponding x, y values (can be NA).
In this example, that would look like this
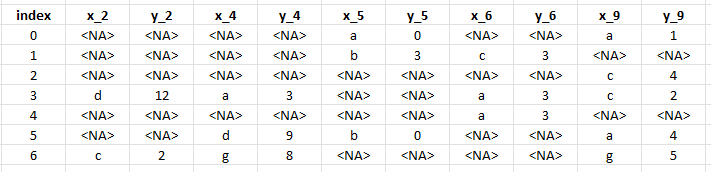
Here, looking at the first row again, (id=5, x=a, y=0) has translated -> (x_5=a, y_5=0) and (id=9, x=a, y=1) -> (x_9=a, y_9=1). There are no observations for any other locations. So those are <NA>
Have been trying all combinations of .pivot I can think of but can't manage it.
MRE to produce the example DataFrame's:
import pandas as pd
df_before = pd.DataFrame(
[
[5, 'a', '0', 9, 'a', '1'],
[5, 'b', '3', 6, 'c', '3'],
[9, 'c', '4'],
[2, 'd', '12', 6, 'a', '3', 9, 'c', '2', 4, 'a', '3'],
[6, 'a', '3'],
[5, 'b', '0', 9, 'a', '4', 4, 'd', '9'],
[2, 'c', '2', 9, 'g', '5', 4, 'g', '8']
],
columns=['id_0','x_0','y_0', 'id_1', 'x_1', 'y_1', 'id_2', 'x_2', 'y_2', 'id_3', 'x_3', 'y_3']
).fillna(pd.NA)
df_after = pd.DataFrame(
[
[pd.NA, pd.NA, pd.NA, pd.NA, 'a', '0', pd.NA, pd.NA, 'a', '1'],
[pd.NA, pd.NA, pd.NA, pd.NA, 'b', '3', 'c', '3', pd.NA, pd.NA],
[pd.NA, pd.NA, pd.NA, pd.NA, pd.NA, pd.NA, pd.NA, pd.NA, 'c', '4'],
['d', '12', 'a', '3', pd.NA, pd.NA, 'a', '3', 'c', '2'],
[pd.NA, pd.NA, pd.NA, pd.NA, pd.NA, pd.NA, 'a', '3', pd.NA, pd.NA],
[pd.NA, pd.NA, 'd', '9', 'b', '0', pd.NA, pd.NA, 'a', '4'],
['c', '2', 'g', '8', pd.NA, pd.NA, pd.NA, pd.NA, 'g', '5']
],
columns=['x_2', 'y_2', 'x_4', 'y_4', 'x_5', 'y_5', 'x_6', 'y_6', 'x_9', 'y_9']
)
CodePudding user response:
Your operation is essentially melt/wide_to_long, and pivot back:
out = (pd.wide_to_long(df_before.reset_index(),
stubnames=['id_','x_','y_'],
i='index',
j='old_id'
)
.groupby(['index','id_']).first().unstack('id_')
.sort_index(level=[1,0], axis=1)
)
out.columns = [f'{x}{int(y)}' for x,y in out.columns]
Output:
x_2 y_2 x_4 y_4 x_5 y_5 x_6 y_6 x_9 y_9
index
0 NaN NaN NaN NaN a 0 NaN NaN a 1
1 NaN NaN NaN NaN b 3 c 3 NaN NaN
2 NaN NaN NaN NaN NaN NaN NaN NaN c 4
3 d 12 a 3 NaN NaN a 3 c 2
4 NaN NaN NaN NaN NaN NaN a 3 NaN NaN
5 NaN NaN d 9 b 0 NaN NaN a 4
6 c 2 g 8 NaN NaN NaN NaN g 5
CodePudding user response:
Try:
def fn(x):
m = x.notna() & ~x.index.str.startswith("id")
return {
f"{a}_" str(int(x[f"id_{b}"])): v
for (a, b), v in zip(map(lambda v: v.split("_"), x[m].index), x[m])
}
x = pd.DataFrame(df_before.apply(fn, axis=1).to_list())
print(x[sorted(x.columns, key=lambda v: int(v.split("_")[1]))])
Prints:
x_2 y_2 x_4 y_4 x_5 y_5 x_6 y_6 x_9 y_9
0 NaN NaN NaN NaN a 0 NaN NaN a 1
1 NaN NaN NaN NaN b 3 c 3 NaN NaN
2 NaN NaN NaN NaN NaN NaN NaN NaN c 4
3 d 12 a 3 NaN NaN a 3 c 2
4 NaN NaN NaN NaN NaN NaN a 3 NaN NaN
5 NaN NaN d 9 b 0 NaN NaN a 4
6 c 2 g 8 NaN NaN NaN NaN g 5