How can we find new IDs added per month? I have this dataframe.
import pandas as pd
import numpy as np
# data stored in dictionary
details = {
'address_id': [111, 111, 111, 111, 222, 222, 222, 333, 333, 444, 444, 555, 555, 777],
'mydate':['2022-01-24', '2022-01-24', '2022-03-28', '2022-03-28', '2022-01-24', '2022-01-24', '2022-03-28', '2022-01-24', '2022-03-28', '2022-01-24', '2022-03-28', '2022-01-24', '2022-04-16', '2022-03-28']
}
df = pd.DataFrame(details)
df
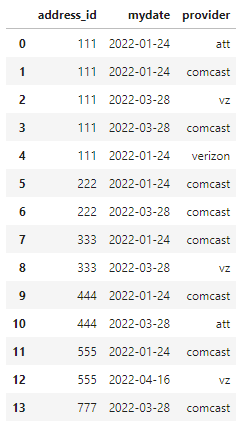
I can easily group by date and find unique IDs
df_id = df.groupby('mydate').address_id.nunique().reset_index()
df_id
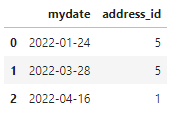
But how can I list out newly added IDs and recently dropped IDs? How can I create a list, or dataframe, showing me that 555 did not exist for '2022-03-28', so this is an add. Also, 111, 222, 333, 444, and 777 were all dropped for '2022-04-16'
CodePudding user response:
Create a set for each day:
daily_ids = df.groupby('mydate')['address_id'].agg(set).sort_index(ascending=False)
print(daily_ids)
# Output:
mydate
2022-04-16 {555}
2022-03-28 {777, 333, 111, 444, 222}
2022-01-24 {555, 333, 111, 444, 222}
Name: address_id, dtype: object
Now we can check the differences by looking at the differences between sets.
# Recently Removed:
>>> daily_ids.diff().shift(-1)
mydate
2022-04-16 {777, 333, 111, 444, 222}
2022-03-28 {555}
2022-01-24 NaN
Name: address_id, dtype: object
# Recently Added:
>>> daily_ids.diff(-1)
mydate
2022-04-16 {555}
2022-03-28 {777}
2022-01-24 NaN
Name: address_id, dtype: object
CodePudding user response:
df_id['unique'] = df.groupby('mydate')['address_id'].agg(set).set_axis(df_id.index)
df_id['new'] = sets_of_ids['address_id'].diff()
df_id['dropped'] = sets_of_ids['address_id'].diff(-1).shift()
df_id
Result:
mydate address_id unique new dropped
0 2022-01-24 5 {555, 333, 111, 444, 222} NaN NaN
1 2022-03-28 5 {777, 333, 111, 444, 222} {777} {555}
2 2022-04-16 1 {555} {555} {777, 333, 111, 444, 222}