I have a tgt table that has like 20 numerical columns that I color based on their value. Additionally, I have each row alternating between grey and white. I would like to make the table not show NA values.
Here is an example table:
library(gt)
library(magrittr)
id <- 1:10
res1 <- sample(1:20, 10)
nm2 <-
c("red",
"purple",
"green",
"turtle",
"name",
"dog",
"cat",
"horse",
"space",
"planet")
res3 <- sample(1:20, 10)
nm4 <- nm2
# Add NAs
res1[6] <- NA
nm2[6] <- "NA"
res3[4] <- NA
nm4[4] <- "NA"
df <- data.frame(id, res1, nm2, res3, nm4)
pal <-
RColorBrewer::brewer.pal(8, "RdYlGn") %>% gt::adjust_luminance(-1.0)
plot <-df %>%
gt() %>%
tab_style(style = cell_fill("lightgrey"),
locations = cells_body(rows = seq(1, nrow(df), by = 2))) %>%
data_color(
columns = colnames(df)[grep("res", colnames(df))],
colors = scales::col_numeric(palette = pal,
domain = c(0, 20))
)
The only way I currently know how to do that is to manually change the text and color of each column based on whether or not there is a NA, but doing this:
tab_style(
style = list(cell_text("white"),
cell_fill("white")),
locations = cells_body(
columns = c("res1", "nm2"),
rows = is.na(df$res1) & row_number(df$res1) ==seq(0, nrow(df), by = 2)
)
) %>%
tab_style(
style = list(cell_text("lightgrey"),
cell_fill("lightgrey")),
locations = cells_body(
columns = c("res1", "nm2"),
rows = is.na(df$res1) & row_number(df$res1) ==seq(1, nrow(df), by = 2)
)
)
I want all 10 IDs to show regardless of whether or not any of the values in that row are NA. Is there anyway to do this more efficiently?
CodePudding user response:
TBMK your approach to do this manually is the way to go. However, IMHO you could simplify your code a bit by setting the na.color used by data_color to "white" so that you only have to take care of NA values in rows with a grey background. Additionally, you could simplify even further by using a custom function instead of duplicating the code for each column.
Note 1: I use seq_along(...) %% 2 == 1 to apply tab_style to only uneven rows.
Note 2: I slightly adjusted your example data to include an NA in an uneven row, i.e. row 5.
library(gt)
library(magrittr)
tab_style_na <- function(data, col) {
tab_style(
data,
style = list(cell_fill("lightgrey")),
locations = cells_body(
columns = all_of(col),
rows = is.na(!!sym(col)) & seq_along(!!sym(col)) %% 2 == 1
)
)
}
df %>%
gt() %>%
tab_style(
style = cell_fill("lightgrey"),
locations = cells_body(rows = seq(1, nrow(df), by = 2))
) %>%
data_color(
columns = colnames(df)[grep("res", colnames(df))],
colors = scales::col_numeric(
palette = pal,
domain = c(0, 20),
na.color = "transparent"
)
) %>%
tab_style_na("res1") %>%
tab_style_na("res3")
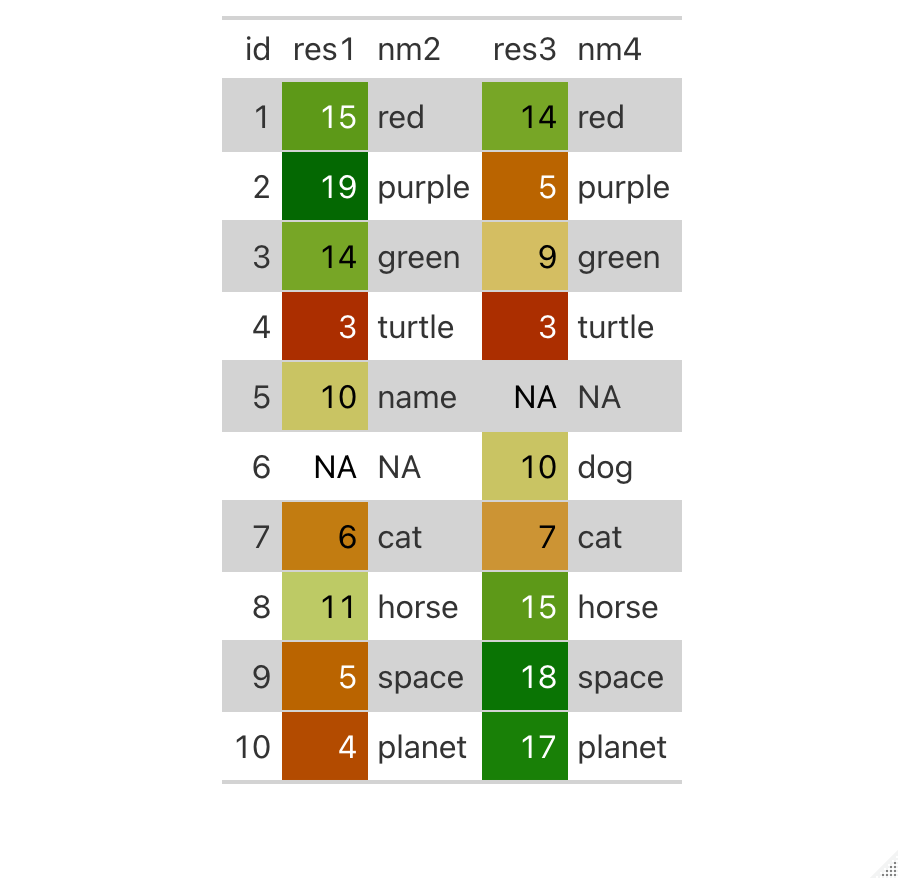
DATA
set.seed(123)
id <- 1:10
res1 <- sample(1:20, 10)
nm2 <-
c(
"red",
"purple",
"green",
"turtle",
"name",
"dog",
"cat",
"horse",
"space",
"planet"
)
res3 <- sample(1:20, 10)
nm4 <- nm2
# Add NAs
res1[6] <- NA
nm2[6] <- "NA"
res3[5] <- NA
nm4[5] <- "NA"
df <- data.frame(id, res1, nm2, res3, nm4)
CodePudding user response:
library(dplyr)
library(gt)
library(magrittr)
id <- 1:10
res1 <- sample(1:20, 10)
nm2 <-
c("red",
"purple",
"green",
"turtle",
"name",
"dog",
"cat",
"horse",
"space",
"planet")
res3 <- sample(1:20, 10)
nm4 <- nm2
# Add NAs
res1[6] <- NA
nm2[6] <- "NA"
res3[4] <- NA
nm4[4] <- "NA"
df <- data.frame(id, res1, nm2, res3, nm4)
pal <-
RColorBrewer::brewer.pal(8, "RdYlGn") %>% gt::adjust_luminance(-1.0)
## omit NAs here
#df <- na.omit(df)
plot <-df %>%
gt() %>%
tab_style(style = cell_fill("lightgrey"),
locations = cells_body(rows = seq(1, nrow(df), by = 2))) %>%
data_color(
columns = colnames(df)[grep("res", colnames(df))],
colors = scales::col_numeric(palette = pal,
domain = c(0, 20),
na.color = "transparent")
)