Well, let me explain what im trying to achieve.
I have a data.frame just like this:
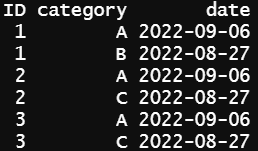
And im trying to use pivot_wider to keep one ID per row and spread the other columns like this:
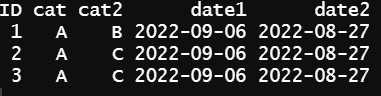
Im strugling with pivot_wider, values_from argument... Any toughts?
Heres my example df
df<- data.frame(ID = c(1,1,2,2,3,3),
category = c("A","B","A","C","A","C"),
date = c(Sys.Date(), Sys.Date()-10, Sys.Date(),
Sys.Date()-10, Sys.Date(), Sys.Date()-10))
CodePudding user response:
Create a row sequence by 'ID', use the sequence column as names_from and values_from as 'category' and 'date' in the pivot_wider
library(dplyr)
library(data.table)
library(tidyr)
df %>%
mutate(rn = rowid(ID)) %>%
pivot_wider(names_from = rn, values_from = c(category, date), names_sep = "")
-output
# A tibble: 3 × 5
ID category1 category2 date1 date2
<dbl> <chr> <chr> <date> <date>
1 1 A B 2022-09-06 2022-08-27
2 2 A C 2022-09-06 2022-08-27
3 3 A C 2022-09-06 2022-08-27
Or using row_number() after grouping to create the sequence column
df %>%
group_by(ID) %>%
mutate(rn = row_number()) %>%
ungroup %>%
pivot_wider(names_from = rn, values_from = c(category, date), names_sep = "")