Is there a difference between the below two queries?
SELECT DISTINCT * FROM TABLE
I was wondering if the above is the same as:
SELECT * FROM TABLE
I do understand that when DISTINCT keyword is used with COLUMN NAME, it returns only unique values in that column but I want to understand what happens if you use DISTINCT * instead.
CodePudding user response:
Assuming your table had only three columns, the two queries in question would be:
SELECT DISTINCT col1, col2, col3 FROM yourTable
SELECT col1, col2, col3 FROM yourTable
The difference here is that should a given (col1, col2, col3) tuple appear more than once in the table, the first distinct query would only report it once, while the second query would report all duplicate records.
CodePudding user response:
SELECT * statement is used for returning all the values in the table column.
SELECT DISTINCT statement is used for returning only distinct (different) values from a column.
CodePudding user response:
Assuming that you have following
Create Table DataTable
(
Id Integer,
col1 Varchar(20),
col2 Varchar(20)
);
Insert Into DataTable Values(1,'AAA','111')
Insert Into DataTable Values(2,'BBB','222')
Insert Into DataTable Values(3,'CCC','333')
Insert Into DataTable Values(1,'AAA','111')
Insert Into DataTable Values(2,'BBB','222')
Insert Into DataTable Values(2,'BBB','333')
When You Used Following Query
Select * from DataTable
The Following Output You See, its return all the rows
| Id | Col1 | Col2 |
|---|---|---|
| 1 | AAA | 111 |
| 2 | BBB | 222 |
| 3 | CCC | 333 |
| 1 | AAA | 111 |
| 2 | BBB | 222 |
| 2 | BBB | 333 |
But When You Used Distinct With Select Query As Per Following
Select Distinct * from DataTable
The Following Output You See, its return only distinct rows means ignore the duplicate rows
| Id | Col1 | Col2 |
|---|---|---|
| 1 | AAA | 111 |
| 2 | BBB | 222 |
| 2 | BBB | 333 |
| 3 | CCC | 333 |
Another Example Of Distinct With Two Columns
Select Distinct Id,Col1 from DataTable
| Id | Col1 |
|---|---|
| 1 | AAA |
| 2 | BBB |
| 3 | CCC |
CodePudding user response:
table T has n column: C1, C2, .. Cn
SELECT * get all set {C1, C2, ... Cn}
SELECT DISTINCT * get all unique set {C1, C2, ... Cn}
For example
drop table furniture;
/
CREATE TABLE furniture (
room VARCHAR2(50),
appliance VARCHAR2(50)
);
INSERT INTO furniture VALUES (
'BEDROOM',
'BED'
);
INSERT INTO furniture VALUES (
'LIVING ROOM',
'SOFA'
);
INSERT INTO furniture VALUES (
'TV ROOM',
'TV'
);
INSERT INTO furniture VALUES (
'ALL',
'LAMP'
);
INSERT INTO furniture VALUES (
'ALL',
'LAMP'
);
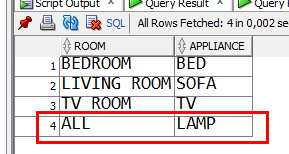
Result of select * from furniture; is
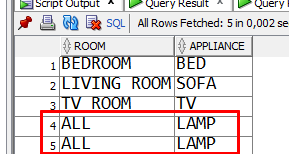
Result of select distinct * from furniture; is