How can I linearly interpolate row-wise in a pandas dataframe, and append the results as a new column?
Example:
df = pd.DataFrame({"x1": [0, 0, 0], "x2": [10, 10, 10]})
display(df)
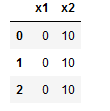
The columns contain the x-value which can be defined as cols = [1,2]
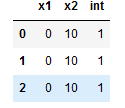
I want to interpolate at a value of x=1.1. The expected output is this:
I tried this, below, but received ValueError: object of too small depth for desired array
df["int"] = df.apply(lambda row: np.interp(cols, 1.1, row[df.columns.values]), axis=1)
Note that the actual df contains different numbers in each row and column; this example here is simple for proof of concept check. Also, there are 5000 columns and 200 rows in the real dataframe.
Edit, Another Failed Attempt
Based on the comment linking to Row-wise Interpolation in dataframe using interp1d, I tried the following and received the same error.
cols = [1,2]
df["int"] = df.apply(lambda x: np.interp(cols, 1.1, df[list(df.columns)]), axis=1)
CodePudding user response:
You can use DataFrame.interpolate:
cols = [1,2]
# save column names and set X values
old_cols = list(df.columns) ['int']
df = df.set_axis(cols, axis=1)
# add NaN column
df[1.1] = np.nan
# interpolate using index and restore column names
df = (df.interpolate(method='index', axis=1)
.set_axis(old_cols, axis=1)
)
Output (modified example):
x1 x2 int
0 0.0 10.0 1.0
1 0.0 5.0 0.5
2 10.0 20.0 11.0