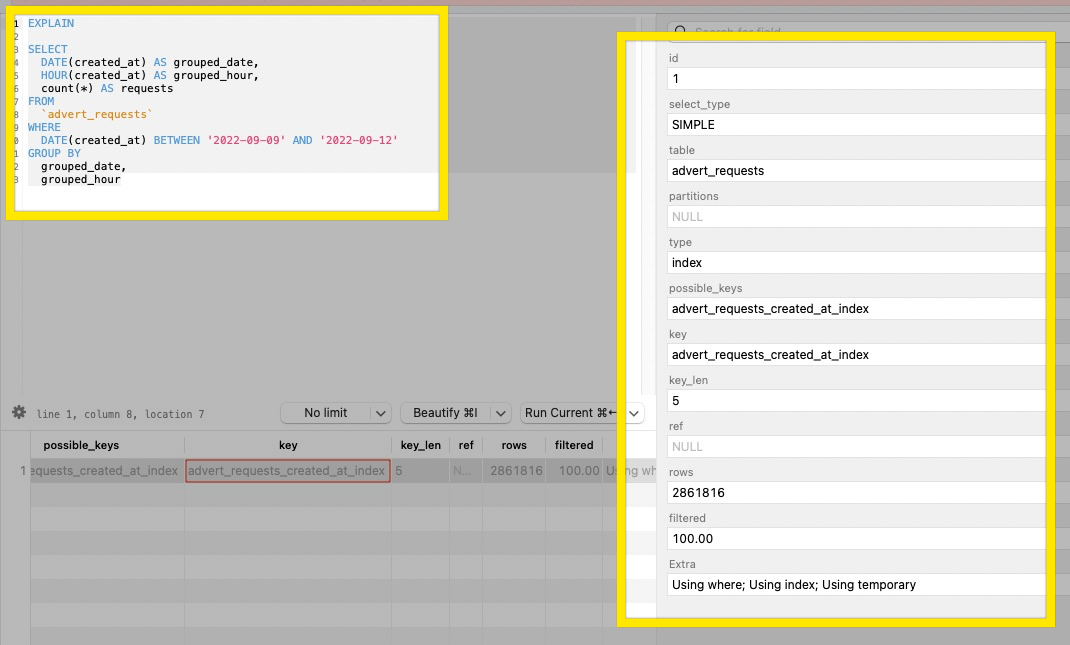
I have a MySQL table with around 2m rows in it. I'm trying to run the below query and each time it's taken over 5 seconds to get results. I have an index on created_at column. Below is the EXPLAIN output.
Is this expected?
Thanks in advance.
SELECT
DATE(created_at) AS grouped_date,
HOUR(created_at) AS grouped_hour,
count(*) AS requests
FROM
`advert_requests`
WHERE
DATE(created_at) BETWEEN '2022-09-09' AND '2022-09-12'
GROUP BY
grouped_date,
grouped_hour
CodePudding user response:
The EXPLAIN shows type: index which is an index-scan. That is, it is using the index, but it's iterating over every entry in the index, like a table-scan does for rows in the table. This is supported by rows: 2861816 which tells you the optimizer's estimate of quantity of index entries it will examine (this is a rough number). This is much more expensive than examining only the rows matching the condition, which is the benefit we look for from an index.
So why is this?
When you use any function on an index column in your search like this:
WHERE
DATE(created_at) BETWEEN '2022-09-09' AND '2022-09-12'
It spoils the benefit of the index for reducing the number of rows examined.
MySQL's optimizer doesn't have any intelligence about the result of functions, so it can't infer that the order of return values will be in the same order as the index. Therefore it can't use the fact that the index is sorted to narrow down the search. You and I know that this is natural for DATE(created_at) to be in the same order as created_at, but the query optimizer doesn't know this. There are other functions like MONTH(created_at) where the results are definitely not in sorted order, and MySQL's optimizer doesn't attempt to know which function's results are reliably sorted.
To fix your query, you can try one of two things:
Use an expression index. This is a new feature in MySQL 8.0:
ALTER TABLE `advert_requests` ADD INDEX ((DATE(created_at)))
Notice the extra redundant pair of parentheses. These are required when defining an expression index. The index entries are the results of that function or expression, not the original values of the column.
If you then use the same expression in your query, the optimizer recognizes that and uses the index.
mysql> explain SELECT DATE(created_at) AS grouped_date, HOUR(created_at) AS grouped_hour, count(*) AS requests FROM `advert_requests` WHERE DATE(created_at) BETWEEN '2022-09-09' AND '2022-09-12' GROUP BY grouped_date, grouped_hour\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: advert_requests
partitions: NULL
type: range <-- much better than 'index'
possible_keys: functional_index
key: functional_index
key_len: 4
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where; Using temporary
If you use MySQL 5.7, you can't use expression indexes directly, but you can use a virtual column and define an index on the virtual column:
ALTER TABLE advert_requests
ADD COLUMN created_at_date DATE AS (DATE(created_at)),
ADD INDEX (created_at_date);
The trick of the optimizer recognizing the expression still works.
If you use a version of MySQL older than 5.7, you should upgrade regardless. MySQL 5.6 and older versions are past their end of life by now, and they are security risks.
The second thing you could do is refactor your query so the created_at column is not inside a function.
WHERE
created_at >= '2022-09-09' AND created_at < '2022-09-13'
When comparing a datetime to a date value, the date value is implicitly at 00:00:00.000 time. To include every fraction of a second up to 2022-09-12 23:59:59.999, it's simpler to just use < '2022-09-13'.
The EXPLAIN of this shows that it uses the existing index on created_at.
mysql> explain SELECT DATE(created_at) AS grouped_date, HOUR(created_at) AS grouped_hour, count(*) AS requests FROM `advert_requests` WHERE created_at >= '2022-09-09' AND created_at < '2022-09-13' GROUP BY grouped_date, grouped_hour\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: advert_requests
partitions: NULL
type: range <-- not 'index'
possible_keys: created_at
key: created_at
key_len: 6
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition; Using temporary
This solution works on older versions of MySQL as well as 5.7 and 8.0.
CodePudding user response:
If I understand the EXPLAIN correctly, it's able to use the index to implement the WHERE filtering. But this is returning 2.8 million rows, which then have to be grouped by date and hour, and this is a slow process.
You may be able to improve it by creating virtual columns for the date and hour, and index these as well.
ALTER TABLE advert_requests
ADD COLUMN created_date AS DATE(created_at), ADD column created_hour AS HOUR(created_at), ADD INDEX (created_date, created_hour);
CodePudding user response:
Use explain analysis and check whether it is Index range scan or not. if not follow this link:
https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html
(Note that sometimes full table scan can be better if most of the timestamps in the table belong to the selected date range. As I know in such case optimization is not trivial)