Having a dataframe as below:
df1 = pd.DataFrame({'Name1':['A','Q','A','B','B','C','C','C','E','E','E'],
'Name2':['B','C','D','C','D','D','A','B','A','B','C'],'Marks2':[10,20,6,50, 88,23,140,9,60,65,70]})
df1
#created a new frame
new=df1.loc[(df1['Marks2'] <= 50)]
new
#created a pivot table
temp=new.pivot_table(index="Name1", columns="Name2", values="Marks2")
temp
I tried to re-index the pivot table.
new_value=['E']
order = new_value list(temp.index.difference(new_value))
matrix=temp.reindex(index=order, columns=order)
matrix
But the values related to 'E' is not present in pivot table. dataframe df1 contains values related with E. I need to add the value related to E in the pivot_table
Expected output:
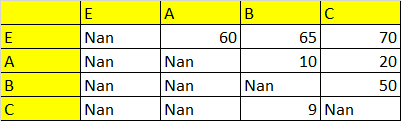
CodePudding user response:
Based on the comments my understanding of the intended result:
E A B C D
E NaN 60.0 65.0 70.0 NaN
A NaN NaN 10.0 NaN 6.0
C NaN NaN 9.0 NaN 23.0
Q NaN NaN NaN 20.0 NaN
Code:
Activate the inlcuded #print() statements to see what the steps do.
Especially at the header 'formatting' in the end you may adapt acc. your needs.
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'Name1':['A','Q','A','B','B','C','C','C','E','E','E'],
'Name2':['B','C','D','C','D','D','A','B','A','B','C'],
'Marks2':[10,20,6,50, 88,23,140,9,60,65,70]})
df1['Marks2'] = np.where( (df1['Marks2'] >= 50) & (df1['Name1'] != 'E'),
np.nan, df1['Marks2'])
#print(df1)
temp=df1.pivot_table(index="Name1", columns="Name2", values="Marks2")
#print(temp)
name1_to_move = 'E'
# build new index with name1_to_move at the start (top in df idx)
idx=temp.index.tolist()
idx.pop(idx.index(name1_to_move))
idx.insert(0, name1_to_move)
# moving the row to top by reindex
temp=temp.reindex(idx)
#print(temp)
temp.insert(loc=0, column=name1_to_move, value=np.nan)
#print(temp)
temp.index.name = None
#print(temp)
temp = temp.rename_axis(None, axis=1)
print(temp)