This is a continuation of the following question:
Pandas can't "reindex from a duplicate axis" which is what this approach relies on and really, linear interpolation won't really work either when you have two identical x values and two distinct y values.
An extra layer of QA could be done on the input data, inspecting it beforehand like my snippet, and doing a groupby average or something like that if appropriate.
The only other thing I'd point out is using a range (i.e. integers) for the reindexing is kinda unneccessary --> you should be able to reindex with floats to any step size you want.
CodePudding user response:
Thanks for the answer gmerrit123, but I believe I remove that error by using this line:
df = df[~df.index.duplicated()]
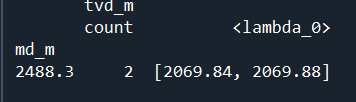
What solved it for me was converting the md column to INT, as the reindexing was running with step = 1 meter, but the raw data had 2 decimal points.
mdcol, tvdcol = 'md_m', 'tvd_m'
df = data[[mdcol, tvdcol]].copy()#.set_index(mdcol)#.reindex(index = range(int(df.index.min()), int(df.index.max())))
df[mdcol] = df[mdcol].astype('int')
df = df.set_index(mdcol)
df = df[~df.index.duplicated()]
data_intp = (df.reindex(index = range(int(df.index.min()), int(df.index.max() 1)))
.reset_index()
.interpolate()
)