when fitting the CNN model,
training accuracy = 68%
validation accuracy = 63%
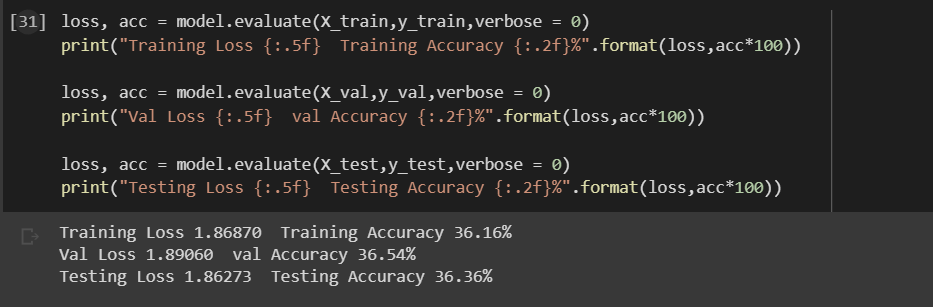
but when I try to evaluate the same CNN model with the same validation data and training data the results are,
Training Loss 1.86870 Training Accuracy = 36.16%
Val Loss 1.89060 val Accuracy = 36.54%
Testing Loss 1.86273 Testing Accuracy = 36.36%
There is a big gap between these accuracies. What can be the reason behind this? The CNN model:
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation ,Dropout, Normalization, AveragePooling2D, BatchNormalization
from tensorflow.keras.optimizers import Adam, Adamax
from tensorflow.python.keras import regularizers
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(height, width, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Conv2D(32, (3, 3), input_shape=(height, width, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Conv2D(32, (3, 3), input_shape=(height, width, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Conv2D(32, (3, 3), input_shape=(height, width, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Conv2D(64, (3, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Dropout(.2))
model.add(Conv2D(64, (3, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Dropout(.2))
model.add(Conv2D(64, (3, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Dropout(.2))
model.add(Conv2D(64, (3, 3), padding='same', activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same', strides=(2)))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(256, activation="relu"))
model.add(BatchNormalization())
model.add(Dropout(.5))
model.add(Dense(126, activation="relu"))
model.add(BatchNormalization())
model.add(Dropout(.5))
model.add(Dense(4,activation='softmax'))
Adam(learning_rate=0.001, name='Adam')
model.compile(optimizer = 'Adam',loss = 'categorical_crossentropy',metrics = ['accuracy'])
epochs = 50
from tensorflow.keras import callbacks
import time
import keras
from keras.callbacks import EarlyStopping
es_callback = keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=20)
datagen = ImageDataGenerator(
horizontal_flip=True,
vertical_flip=True,
featurewise_std_normalization=True,
samplewise_std_normalization=True
)
checkpoint = callbacks.ModelCheckpoint(
filepath='/content/drive/MyDrive/model.{epoch:02d}-{accuracy:.2f}-{val_accuracy:.2f}.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
mode='auto'
)
datagen.fit(X_train)
history5 = model.fit(datagen.flow(X_train,y_train, batch_size=batch_size),
epochs = epochs, validation_data = datagen.flow(X_val,y_val, batch_size=batch_size),
callbacks=[ checkpoint]
)
stop = time.time()
CodePudding user response:
Here, in the fit function, I have augmented training data as well as validation data, which is not correct. Data augmentation is used to expand the training set and generate more diverse images. It should apply only to training data. Test data and validation data must not be touched.