I am trying to scrape a website (website link is given below in code) and all containers are not loading and even if some of them are loaded, the number are not shown. In my case, the number 228 are not loaded.
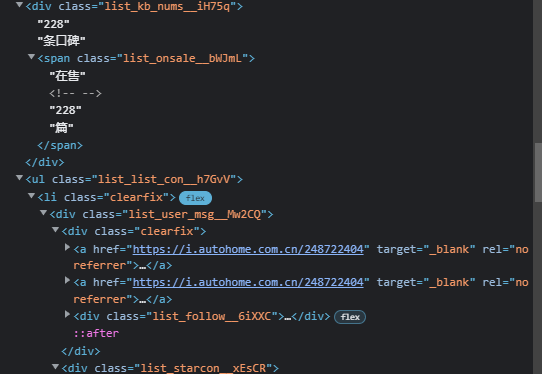
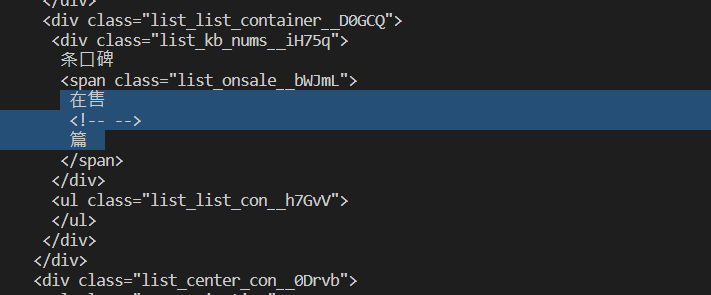
As shown on image, all div are not shown with beautifulsoup, unlike what I inspect.
My code:
page = requests.get("https://k.autohome.com.cn/5213/16665#pvareaid=3454637")
soup = BeautifulSoup(page.content, 'lxml')
print(soup.prettify())
I would actually like to obtain the data below.I am not sure why I could not obtain any data related to it.
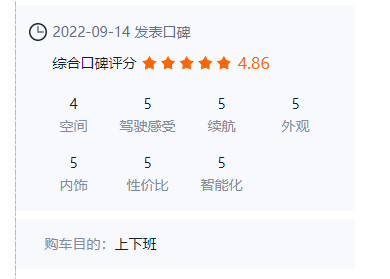
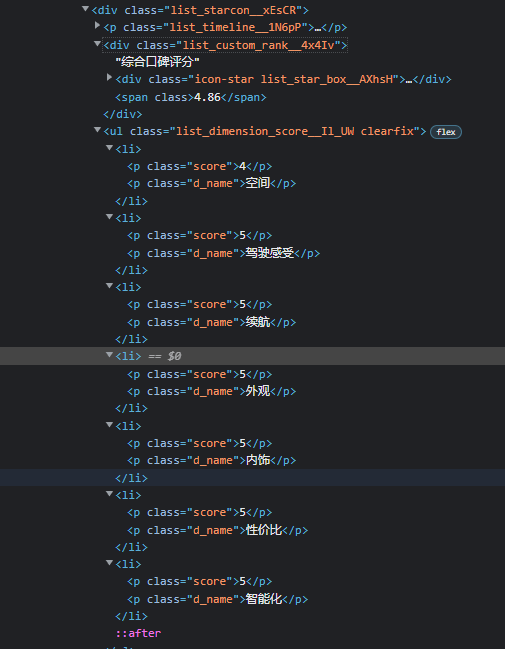
CodePudding user response:
Maybe the page you try to parse is dynamic one.
BS gets the code but javascript hasn't worked yet and so there is no data you need in the code that's gotten by BS.
To check it you can try to do the same but with selenium instead of BS.
CodePudding user response:
That page is being hydrated with information from several APIs, after the original HTML loads. You should inspect Dev tools -Network tab (Under XHR section), have a look at the API endpoints being accessed, and check the data under Preview section see which one is returning the data you need.
For example, here is the data returned by one of the APIs:
import requests
import pandas as pd
r = requests.get('https://k.autohome.com.cn/_next/data/prod-c_1.0.56-p_2.3.4-koubei_pc_nextjs/series/6091.json')
df = pd.json_normalize(r.json()['pageProps']['baseData']['seriesScoreList'])
print(df)
Result printed in terminal:
typeKey typeName score rank
0 3 空间 4.77 0
1 4 驾驶感受 4.55 0
2 6 续航 4.38 0
3 8 外观 4.68 0
4 9 内饰 4.42 0
5 15 性价比 4.85 0
6 40 智能化 4.32 0
Docs for requests: https://requests.readthedocs.io/en/latest/
And relevant docs for pandas: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.json_normalize.html