I have a data structure like the one below.
df <- structure(list(id = c(1, 1, 1, 2, 2, 3, 3, 4, 4), HT = c("L",
"L", "L", "W", "W", "B", "B", "WA", "WA"), HS = c(4, 4, 4, 0,
0, 3, 3, 0, 0), AT = c("N", "N", "N", "M", "M", "S", "S", "BR",
"BR"), AS = c(1, 1, 1, 5, 5, 1, 1, 3, 3), T = c("L", "L", "N",
"W", "M", "B", "S", "WA", "BR"), H_A = c("H", "H", "A", "H",
"A", "H", "A", "H", "A"), S_incorrect_value = c(3, 3, 1, 0, 5,
3, 0, 0, 2), S_corrected_value = c(4, 4, 1, 0, 5, 3, 1, 0, 3)), row.names = c(NA,
-9L), class = c("tbl_df", "tbl", "data.frame"))
However, it contains some inconsistent values that need to be replaced with a new column to be created (S_corrected_value).
The column with the desired values will be in long format, and correspond to values from two other columns. There are also different numbers of rows that make up each case (id). I have left marked in color to be noticed where the data is scraped from.
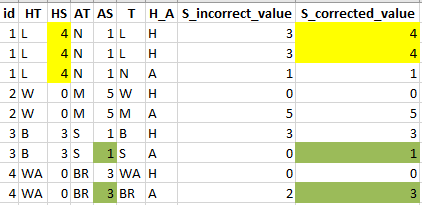
CodePudding user response:
You can use dplyr::case_when() to evaluate the value of H_A and determine what value to replace with.
library(tidyverse)
df %>%
mutate(S_corrected_value_new = case_when(
H_A == "H" ~ HS,
H_A == "A" ~ AS
))
#> # A tibble: 9 × 10
#> id HT HS AT AS T H_A S_incorrect_value S_correc…¹ S_cor…²
#> <dbl> <chr> <dbl> <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 1 L 4 N 1 L H 3 4 4
#> 2 1 L 4 N 1 L H 3 4 4
#> 3 1 L 4 N 1 N A 1 1 1
#> 4 2 W 0 M 5 W H 0 0 0
#> 5 2 W 0 M 5 M A 5 5 5
#> 6 3 B 3 S 1 B H 3 3 3
#> 7 3 B 3 S 1 S A 0 1 1
#> 8 4 WA 0 BR 3 WA H 0 0 0
#> 9 4 WA 0 BR 3 BR A 2 3 3
#> # … with abbreviated variable names ¹S_corrected_value, ²S_corrected_value_new
Created on 2022-09-21 by the reprex package (v2.0.1)