I tried to merge 3 columns from 3 dataframes based on 2 conditions. For example I have the 3 dataframes below called df_a, df_b and df_c
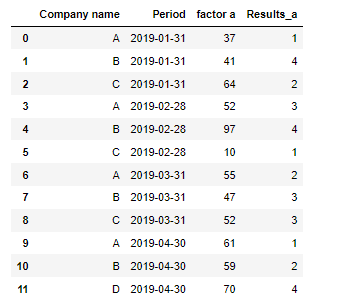
df_a:
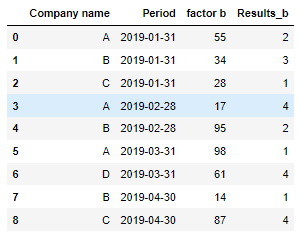
df_b:
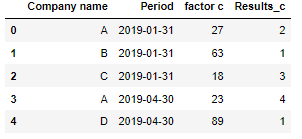
df_c:
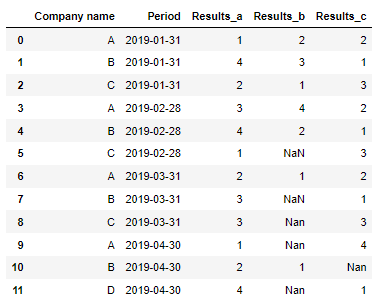
I want to merge the column Results_b from df_b to df_a if they are the same company and in the same period. Also I would like to remove the column of factor a and factor b.
I tried df_merged = pd.merge(df_a, df_b, on=['Company name', 'Period'], how='left') for merging df_a and df_b and it works, but I am not sure how to only merge the column of Results_a and Results_b instead of merging all columns.
Lastly, I would also like to merge the column Results_c from df_c if they are the same company and in the same period. However, df_c data are based on each quarter (or every 3 months) and df_a and df_b are based on every month, so for the months which is not in df_c, I would like the data to be the same from previous available data. I am not so sure how to deal with it.
This is the outcome that I would like to see:
It would be really appreciated if someone can help me!! Thanks a lot
For reproducing the dataframes:
df_a = pd.DataFrame({
'Company name': ['A','B','C','A','B','C','A','B','C','A','B','D'],
'Period': ['2019-01-31','2019-01-31','2019-01-31','2019-02-28','2019-02-28','2019-02-28','2019-03-31','2019-03-31','2019-03-31','2019-04-30','2019-04-30','2019-04-30'],
'factor a': [37,41,64,52,97,10,55,47,52,61,59,70],
'Results_a': [1,4,2,3,4,1,2,3,3,1,2,4]
})
# b
df_b = pd.DataFrame({
'Company name': ['A','B','C','A','B','A','D','B','C'],
'Period': ['2019-01-31','2019-01-31','2019-01-31','2019-02-28','2019-02-28','2019-03-31','2019-03-31','2019-04-30','2019-04-30'],
'factor b': [55,34,28,17,95,98,61,14,87],
'Results_b': [2,3,1,4,2,1,4,1,4]
})
#c
df_c = pd.DataFrame({
'Company name': ['A','B','C','A','D'],
'Period': ['2019-01-31','2019-01-31','2019-01-31','2019-04-30','2019-04-30'],
'factor c': [27,63,18,23,89],
'Results_c' : [2,1,3,4,1],
})```
CodePudding user response:
Use concat:
dfs = [df_a, df_b, df_c]
out = pd.concat([df.set_index(['Company name', 'Period'])
.filter(like='Results_')
for df in dfs],
axis=1).reset_index()
NB. to mimick the left merge, you can add .dropna(subset='Results_a').
output:
Company name Period Results_a Results_b Results_c
0 A 2019-01-31 1.0 2.0 2.0
1 B 2019-01-31 4.0 3.0 1.0
2 C 2019-01-31 2.0 1.0 3.0
3 A 2019-02-28 3.0 4.0 NaN
4 B 2019-02-28 4.0 2.0 NaN
5 C 2019-02-28 1.0 NaN NaN
6 A 2019-03-31 2.0 1.0 NaN
7 B 2019-03-31 3.0 NaN NaN
8 C 2019-03-31 3.0 NaN NaN
9 A 2019-04-30 1.0 NaN 4.0
10 B 2019-04-30 2.0 1.0 NaN
11 D 2019-04-30 4.0 NaN 1.0
12 D 2019-03-31 NaN 4.0 NaN
13 C 2019-04-30 NaN 4.0 NaN
CodePudding user response:
You Can also use merge & update value of column "Results_c" in loop, if required;
# Merge Data Sets
data_frames = [df_a,df_b,df_c]
df_result = reduce(lambda left,right: pd.merge(left,right,on=['Company name', 'Period'],
how='left'), data_frames)
df_result = df_result[[col for col in df_result.columns if "factor" not in col]]
# Updating Results_c values if NaN for the month
lst_period = sorted(list(df_result["Period"].unique()))
for i in range(0,len(lst_period)):
df_temp = df_result[df_result["Period"] == lst_period[i]]
if df_temp["Results_c"].isna().sum() == 3: #Edit this number depending on your company's count... as of now 3 bcz of A,B,C
lst_val = df_result[df_result["Period"] == lst_period[i-1]]["Results_c"]
df_result.loc[df_result["Period"] == lst_period[i],"Results_c"] = list(lst_val)
Hope this Helps...
Company name Period Results_a Results_b Results_c
0 A 2019-01-31 1 2.0 2.0
1 B 2019-01-31 4 3.0 1.0
2 C 2019-01-31 2 1.0 3.0
3 A 2019-02-28 3 4.0 2.0
4 B 2019-02-28 4 2.0 1.0
5 C 2019-02-28 1 NaN 3.0
6 A 2019-03-31 2 1.0 2.0
7 B 2019-03-31 3 NaN 1.0
8 C 2019-03-31 3 NaN 3.0
9 A 2019-04-30 1 NaN 4.0
10 B 2019-04-30 2 1.0 NaN
11 D 2019-04-30 4 NaN 1.0