I am new to web scraping. I am trying to download only the weekly .zip files from the below website. I could able to parse the label and couldn't go beyond that to download the weekly zip files.
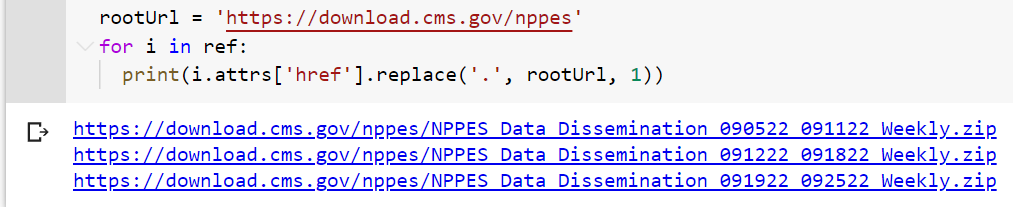
CodePudding user response:
Try the next example
import requests
from bs4 import BeautifulSoup
URL = "https://download.cms.gov/nppes/NPI_Files.html"
r = requests.get(URL)
#print(r.content)
soup = BeautifulSoup(r.content, 'html.parser')
#print(soup.prettify())
links=[]
for ref in soup.select('div.bulletlistleft > ul > li')[2:]:
zip ='https://download.cms.gov/nppes' ref.a.get('href').replace('./','/')
links.append(zip)
print(links)
Output:
['https://download.cms.gov/nppes/NPPES_Data_Dissemination_090522_091122_Weekly.zip', 'https://download.cms.gov/nppes/NPPES_Data_Dissemination_091222_091822_Weekly.zip', 'https://download.cms.gov/nppes/NPPES_Data_Dissemination_091922_092522_Weekly.zip']
CodePudding user response:
Access a tags if there are any:
for i in ref:
if i.a is not None:
print(i.a.get('href'))
CodePudding user response:
The following code will find the links, download the files, and unzip them.
import requests
from bs4 import BeautifulSoup
import os
from urllib.request import urlretrieve
import zipfile
target_folder = os.path.dirname(os.path.realpath(__file__))
base_url = "https://download.cms.gov/nppes"
url = f"{base_url}/NPI_Files.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
elms = soup.select('div.bulletlistleft > ul > li > a')
for elm in elms:
zip_filename = elm.attrs['href'].lstrip('./')
zip_full_url = "/".join((base_url, zip_filename))
target_zip_path = os.path.join(target_folder, zip_filename)
target_zip_dir = ".".join(target_zip_path.split('.')[:-1])
urlretrieve(zip_full_url, target_zip_path)
with zipfile.ZipFile(target_zip_path, 'r') as zip_file:
zip_file.extractall(target_zip_dir)