I'm trying to merge a list of dataframes keeping unique names (avoid duplicating the names that are repeated across all dataframes). I have 4 dataframes with different number of rows each and I need to combine them all so that I only get the participants who took all tests
- I get this, with Nas.
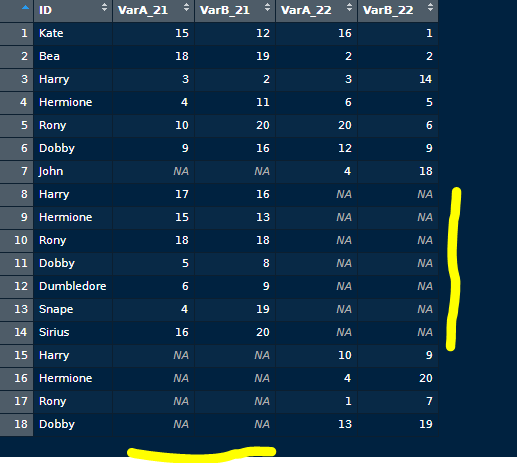
- Variables:
class1Time1 : took VarA and VarB tests in 2021
class2Time1 : took VarA and VarB tests in 2021
class1Time1 : took VarA and VarB tests in 2022
class2Time1 : took VarA and VarB tests in 2022
so, "Var_Year" stands for the grades of each subject in the target year, but note that
not every subject took all tests
- This is a simplified made-up version of my data
### create a similar data frame:
names1 <- c("Mary","John","Kate", "Bea", "Harry", "Hermione", "Rony", "Dobby")
names2 <- c("Harry", "Hermione", "Rony", "Dobby", "Dumbledore", "Snape", "Sirius")
class1Time1 <- data.frame(ID = names1[3:8], VarA_21 = sample(1:20, 6), VarB_21 = sample(1:20, 6))
class2Time1 <- data.frame(ID = names2[1:7], VarA_21 = sample(1:20, 7), VarB_21 = sample(1:20, 7))
class1Time2 <- data.frame(ID = names1[2:8], VarA_22 = sample(1:20, 7), VarB_22 = sample(1:20, 7))
class2Time2 <- data.frame(ID = names2[1:4], VarA_22 = sample(1:20, 4), VarB_22 = sample(1:20, 4))
### So, the only students that took all tests were "Harry" "Hermione" "Rony" "Dobby"
### Ok, now I'm taking all dataframes from the environment and putting them into a list:
together <- grep("class",names(.GlobalEnv), value=TRUE)
##### put into a list
my_list <- do.call("list", mget(together))
### Now I need ONLY the same names from all dataframes
test <- Reduce(function(...) full_join(...), my_list) ### doens't work
### I've tried merge(), rbind(), etc...
- Note:
I've tried to reproduce my actual data, but I couldn't do that without changing my participant's real names, that's why I've made the made-up version, but my actual data looks like this:
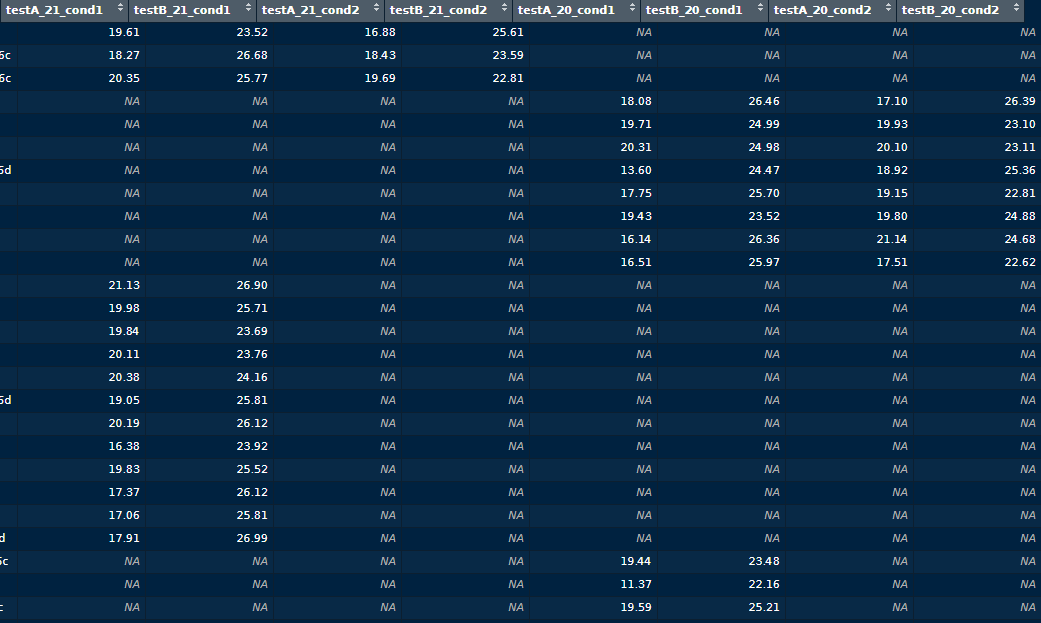
Question 1: how can I join all dataframes so that I have only one row per participants who took all tests ?
Question 2: If I can get Q1, then I believe that a simple
filterwould work afterwards to keep only complete.cases I suppose, right?
I've seen many solutions here including merge(), reduce, rbind, join (by = "ID), but none seemed to help me (I've tried them all). Thanks in advance.
- Edit: I guess that I got closer with
test <- Reduce(function(...) merge(..., all = TRUE, by="ID"), my_list), but it doesn't keep the collumns original names, it duplicates the collumns now
CodePudding user response:
You can use inner joins here, as long as you specify in merge() that you are joining only on ID
Reduce(\(a,b) merge(a,b, by="ID"),my_list)
Output
ID VarA_21.x VarB_21.x VarA_22.x VarB_22.x VarA_21.y VarB_21.y VarA_22.y VarB_22.y
1 Dobby 8 5 19 9 7 13 3 3
2 Harry 14 1 4 16 12 4 20 9
3 Hermione 4 4 14 4 1 17 14 6
4 Rony 18 18 7 18 2 9 7 2
Note: Reduce(merge, my_list) will by default inner join each of these in turn, but there are no matching results in the end because you have common column names beyond just ID (but different "scores in those columns)
CodePudding user response:
As noted in discussion above it's hard to know what might be going on with your data to drop all rows. However there's perhaps a few things you can do to help pinpoint/fix problems:
- at the moment, your four dataframes have duplicated column names, and within each dataframe it doesn't "know" what class it belongs to. That's why columns are being duplicated in the above example. Tidying data would help here by inserting 'class' name to dataframes before merging.
- pivoting to change the shape of the data would make
bind_rowsa simple way to combine all the comparable values across times/tests. - joining all at first would let you visually check that parts are there for expected people, then you can filter across all columns.
Here's a working of the above data using purrr and dplyr to manipulate lists and data frames:
library(tidyverse)
names1 <- c("Mary","John","Kate", "Bea", "Harry", "Hermione", "Rony", "Dobby")
names2 <- c("Harry", "Hermione", "Rony", "Dobby", "Dumbledore", "Snape", "Sirius")
class1Time1 <- data.frame(ID = names1[3:8], VarA_21 = sample(1:20, 6), VarB_21 = sample(1:20, 6))
class2Time1 <- data.frame(ID = names2[1:7], VarA_21 = sample(1:20, 7), VarB_21 = sample(1:20, 7))
class1Time2 <- data.frame(ID = names1[2:8], VarA_22 = sample(1:20, 7), VarB_22 = sample(1:20, 7))
class2Time2 <- data.frame(ID = names2[1:4], VarA_22 = sample(1:20, 4), VarB_22 = sample(1:20, 4))
together <- grep("class",names(.GlobalEnv), value=TRUE)
my_list <- do.call("list", mget(together))
my_list |>
imap( ~ mutate(.x, class = str_extract(.y, "class\\d"))) |>
map(
pivot_longer,
starts_with("Var"),
names_to = "test_time",
values_to = "score"
) |>
reduce(bind_rows) |>
pivot_wider(names_from = c(class, test_time),
values_from = score) |>
# This final line reduces down to only full rows. Can be cut out for checking.
filter(if_all(.fns = ~!is.na(.x)))
#> # A tibble: 4 × 9
#> ID class2_VarA_21 class2_VarB_21 class2_VarA_22 class2_VarB_22
#> <chr> <int> <int> <int> <int>
#> 1 Harry 13 13 8 4
#> 2 Hermione 4 6 9 2
#> 3 Rony 15 15 16 8
#> 4 Dobby 17 19 13 18
#> # … with 4 more variables: class1_VarA_21 <int>, class1_VarB_21 <int>,
#> # class1_VarA_22 <int>, class1_VarB_22 <int>