I'm trying to scrape data-tables from a website
https://newsroom.spotify.com/2020-03-09/36-new-artists-around-the-world-that-are-on-spotifys-radar/
The issue is that the first column entry is merged across multiple rows while the second column has discrete entries:
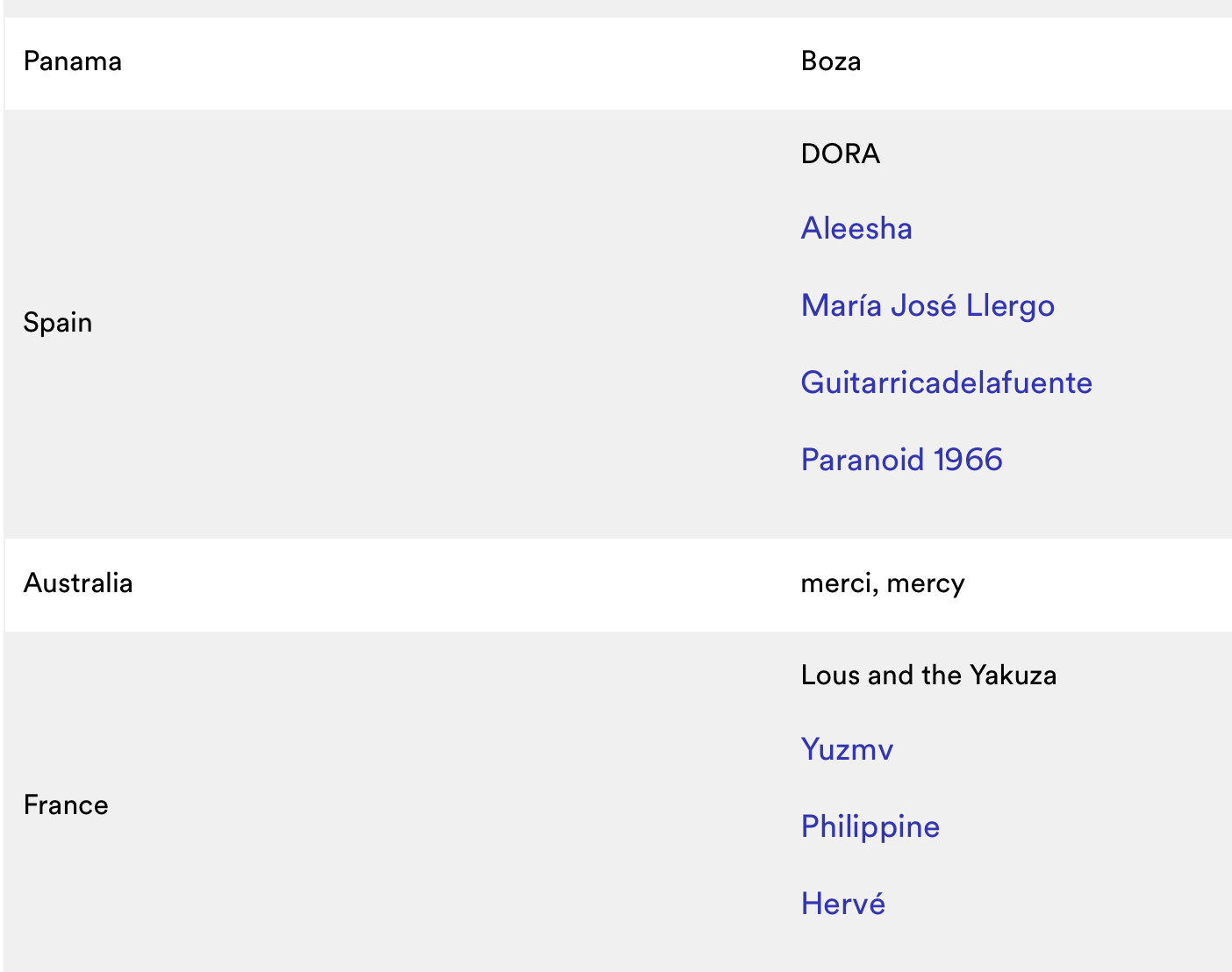
The data table which is being scraped llos something like:

Here different entries in the second column has been merges in a single entry using \n Now I want to shift the merged data to different rows and need some help with the same.
The code for webscraping is
library(rvest
#Spotify's list of new artists to look out for
upcoming_artists <- "https://newsroom.spotify.com/2020-03-09/36-new-artists-around-the-world-that-are-on-spotifys-radar/"
upcoming_artists <- read_html(upcoming_artists)
upcoming_artists <- html_table(upcoming_artists)
The erroneous data frame looks something like:
list(structure(list(X1 = c("United States", "United Kingdom",
"Brazil", "Mexico", "Argentina", "Colombia", "Panama", "Spain",
"Australia", "France", "UAE & Lebanon", "South Africa", "Philippines",
"Indonesia", "Taiwan", "Austria", "Germany", "Netherlands", "Japan\n*RADAR locally titled Early Noise",
"India"), X2 = c("Alaina Castillo", "Young T Bugsey", "Agnes Nunes",
"Silvana Estrada", "Romeo El Santo", "Ela Minus", "Boza", "DORA \nAleesha\nMaría José Llergo\nGuitarricadelafuente\nParanoid 1966",
"merci, mercy", "Lous and the Yakuza \nYuzmv\nPhilippine\nHervé",
"Hollaphonic x Xriss", "Elaine", "SB19\nAugust Wahh", "Mahen\nMonica Karina",
"張若凡RuoFan", "AVEC \nMy Ugly Clementine", "badmómzjay",
"RIMON \nJeangu Macrooy", "Fujii Kaze\nVaundy\nRina Sawayama",
"Mali\nWhen Chai Met Toast\nTaba Chake")), row.names = c(NA,
-20L), class = c("tbl_df", "tbl", "data.frame")))
CodePudding user response:
Use separate_rows from package tidyr to separate a given column into rows.
I have changed the scrapping the a bit.
suppressPackageStartupMessages({
library(rvest)
library(dplyr)
})
#Spotify's list of new artists to look out for
upcoming_artists_link <- "https://newsroom.spotify.com/2020-03-09/36-new-artists-around-the-world-that-are-on-spotifys-radar/"
upcoming_artists <- read_html(upcoming_artists_link)
upcoming_artists %>%
html_elements("tbody") %>%
html_table() %>%
`[[`(1) %>%
tidyr::separate_rows(X2, sep = "\n")
#> # A tibble: 35 × 2
#> X1 X2
#> <chr> <chr>
#> 1 United States Alaina Castillo
#> 2 United Kingdom Young T Bugsey
#> 3 Brazil Agnes Nunes
#> 4 Mexico Silvana Estrada
#> 5 Argentina Romeo El Santo
#> 6 Colombia Ela Minus
#> 7 Panama Boza
#> 8 Spain DORA
#> 9 Spain Aleesha
#> 10 Spain María José Llergo
#> # … with 25 more rows
Created on 2022-10-03 with reprex v2.0.2