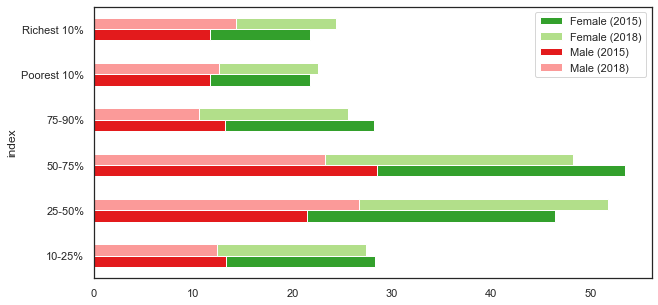
I am trying to obtain a stacked and grouped horizontal bar plot in Python:
female_numbers_2015 = [20882, 31322, 52204, 52205, 31322, 20881]
female_numbers_2018 = [20882, 31322, 52204, 52205, 31322, 20881]
male_numbers_2015 = [11352, 17080, 28380, 28380, 17028, 11351]
male_numbers_2018 = [11454, 17181, 28636, 28634, 17181, 11454]
total_numbers_2015 = [306669]
total_numbers_2018 = [323356]
percent_males_2015 = [i /j * 100 for i,j in zip(male_numbers_2015, total_numbers_2015)]
percent_females_2015 = [i /j * 100 for i,j in zip(female_numbers_2015, total_numbers_2015)]
percent_males_2018 = [i /j * 100 for i,j in zip(male_numbers_2018, total_numbers_2018)]
percent_females_2018 = [i /j * 100 for i,j in zip(female_numbers_2018, total_numbers_2018)]
index = ['Poorest 10%', '10-25%', '25-50%', '50-75%', '75-90%', 'Richest 10%']
df = pd.DataFrame({'percent_females_2015': percent_females_2015,'percent_males_2015': percent_males_2015,
'percent_females_2018': percent_females_2018,'percent_males_2018': percent_males_2018}, index=index)
x = np.arange(len(index))
width = 0.35 # the width of the bars
fig, ax = plt.subplots()
rects1 = ax.barh(x = {male_numbers_2015, female_numbers_2015}, x - width/2, width, label='2015', stacked = True)
rects2 = ax.barh(x = {male_numbers_2018, female_numbers_2018}, x width/2, width, label='2018', stacked = True)
plt.show()
Here I want to group the bars by the index variable, for example, the Poorest 10% category will have two bars associated with that label: the 2015 and 2018 figures. Within each bar, I need to stack the male and female figures, for example in the Poorest 10% category: the 2015 bar will comprise the 2015 percentage of females and the 2015 percentage of males that make up that category.
Your help is greatly appreciated!
CodePudding user response:
There are a few errors in your code and also the logic needs some changes. Firstly, the percentage calculation needs some changes. Below is the code to take the data and lists and dataframe. Note that I have changed some datapoints as your data was giving the same percentages for Male vs. Female.
## Your data, some changes to differentiate the values
female_numbers_2015 = [20882, 31322, 52204, 52205, 31322, 20881]
female_numbers_2018 = [20882, 31322, 52204, 52205, 31322, 20881]
male_numbers_2015 = [13352, 15080, 24380, 32380, 15028, 13351]
male_numbers_2018 = [14454, 14181, 30636, 26634, 12181, 16454]
## Percentage calculation corrected. Need to just divide each entry by sum(vals)
percent_males_2015 = [i /sum(male_numbers_2015) * 100 for i in male_numbers_2015]
percent_females_2015 = [i /sum(female_numbers_2015) * 100 for i in female_numbers_2015]
percent_males_2018 = [i /sum(male_numbers_2018) * 100 for i in male_numbers_2018]
percent_females_2018 = [i /sum(female_numbers_2018) * 100 for i in female_numbers_2018]
myindex = ['Poorest 10%', '10-25%', '25-50%', '50-75%', '75-90%', 'Richest 10%']
Next would be to ensure that the data is arranged in dataframe in the correct order so that pandas plot can see and build the right plot. Basically, create 3 lists - one each for year, Female values and Male values. Then, add them into a dataframe. Adjust the dataframe to have the index as you used it (grouping <10%, ...) and columns by Gender/sex followed by the year (2015, 2018). I did use some of the logic from