I'm trying to subset rows which contain Y in multiple columns while excluding rows which only contain Y in one column.
A solution in R is desired.
This is what my data looks like:
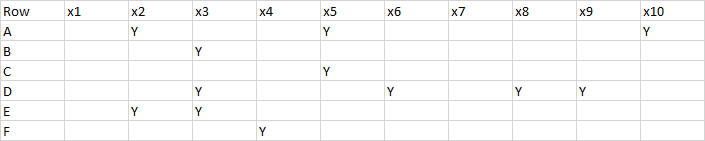
My desired output in R would look like this:

Thanks in advance
CodePudding user response:
library(dplyr)
df <- tibble(w = rbinom(100, 1, 0.5), x = rbinom(100, 1, 0.5), y = rbinom(100, 1, 0.5)) |>
mutate(across(everything(), ~ if_else(.x == 1, "y", NA_character_)))
count_if <- function(x) { if_else(x == "y", 1, 0)}
df |>
rowwise() |>
mutate(count = sum(count_if(c_across(everything())), na.rm = TRUE)) |>
ungroup() |>
filter(count > 1)
# A tibble: 51 × 4
w x y count
<chr> <chr> <chr> <dbl>
1 y NA y 2
2 y y NA 2
3 NA y y 2
4 y y y 3
5 NA y y 2
6 y y NA 2
7 y y NA 2
8 y y NA 2
9 NA y y 2
10 NA y y 2
CodePudding user response:
The idea is to convert your matrix to a numeric matrix containing ones and zeroes, sum the rows, and take only those rows whose sum is 1. See below. I don't recommend defining your data this way; it was just the quickest way I could reproduce your data.
rowA=c(' ','Y',' ',' ','Y',' ',' ',' ',' ','Y')
rowB=c(' ',' ','Y',' ',' ',' ',' ',' ',' ',' ')
rowC=c(' ',' ',' ','Y',' ',' ',' ',' ',' ',' ')
rowD=c(' ',' ','Y',' ',' ','Y',' ','Y','Y',' ')
rowE=c(' ','Y','Y',' ',' ',' ',' ',' ',' ',' ')
rowF=c(' ',' ',' ','Y',' ',' ',' ',' ',' ',' ')
my.data=rbind(rowA,rowB,rowC,rowD,rowE,rowF)
rownames(my.data)=LETTERS[1:6]
step2=ifelse(my.data=='Y',1,0)
v=rowSums(step2)
my.data[v>1,]
Gives the following output:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
A " " "Y" " " " " "Y" " " " " " " " " "Y"
D " " " " "Y" " " " " "Y" " " "Y" "Y" " "
E " " "Y" "Y" " " " " " " " " " " " " " "
You could also avoid creating meaningless variables by combining into fewer lines.
my.data[rowSums(ifelse(my.data=='Y',1,0))>1,]