I have the following dataframe (df) with a column 'date' and 'values'. I am looking for a solution how to create a new dataframe from the variables start_MM_DD and end_MM_DD (month and day). For each year a column with the corresponding values should be created. the data frame "df" can start earlier or data can be missing, depending on how the variables start.
import pandas as pd
import numpy as np
df = pd.DataFrame({'date':pd.date_range(start='2020-01-03', end='2022-01-10')})
df['randNumCol'] = np.random.randint(1, 6, df.shape[0])
start_MM_DD = '01-01'
end_MM_DD = '01-15'
the new dataframe should look like:
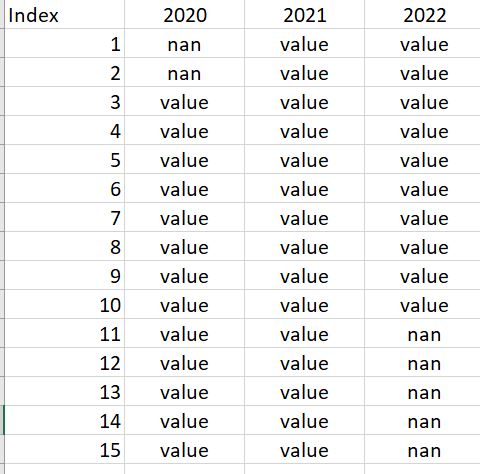
CodePudding user response:
# create your date range; the year does not matter
d_range = pd.date_range('2022-01-01', '2022-01-15').strftime('%m-%d')
# use boolean indexing to filter your frame based on the months and days you want
new = df[df['date'].dt.strftime('%m-%d').isin(d_range)].copy()
# get the year from the date column
new['year'] = new['date'].dt.year
# pivot the frame
new['date'] = new['date'].dt.strftime('%m-%d')
print(new.pivot('date', 'year', 'randNumCol'))
year 2020 2021 2022
date
01-01 NaN 3.0 5.0
01-02 NaN 4.0 2.0
01-03 2.0 4.0 3.0
01-04 3.0 3.0 3.0
01-05 2.0 2.0 4.0
01-06 5.0 5.0 3.0
01-07 1.0 3.0 3.0
01-08 2.0 5.0 2.0
01-09 2.0 2.0 5.0
01-10 5.0 5.0 2.0
01-11 5.0 5.0 NaN
01-12 2.0 3.0 NaN
01-13 1.0 2.0 NaN
01-14 1.0 3.0 NaN
01-15 4.0 3.0 NaN
CodePudding user response:
This is just a pivot table that has been filtered by dates:
import pandas as pd
import numpy as np
df = pd.DataFrame({'date':pd.date_range(start='2020-01-03', end='2022-01-10')})
df['randNumCol'] = np.random.randint(1, 6, df.shape[0])
df = (
df.loc[(df['date'].dt.month.eq(1)) & (df['date'].dt.day.between(1,15))]
.pivot_table(index=df['date'].dt.day,
columns=df['date'].dt.year)
).droplevel(0, axis=1).rename_axis(None)
print(df)
Output
date 2020 2021 2022
1 NaN 2.0 1.0
2 NaN 5.0 4.0
3 3.0 1.0 2.0
4 3.0 1.0 2.0
5 4.0 5.0 5.0
6 5.0 1.0 4.0
7 2.0 4.0 2.0
8 4.0 3.0 3.0
9 5.0 5.0 3.0
10 4.0 3.0 3.0
11 1.0 1.0 NaN
12 2.0 2.0 NaN
13 1.0 4.0 NaN
14 3.0 2.0 NaN
15 1.0 3.0 NaN