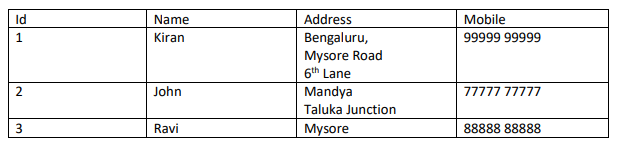
I need to read a df from a pdf file and here is an example table
So far I was able to read the data as raw lines with the following chunk
library(pdftools)
library(tidyverse)
pdf_file <- pdf_text("exm.pdf")
raw_df <- pdf_file %>%
read_lines() %>%
data.frame() %>%
rename(rawline = 1)
raw_df <- raw_df %>%
mutate(
rawline = str_replace(string = rawline,
pattern = "^ \\s*",
replacement = "")
)
here is the structure of raw df
> raw_df
rawline
1 Id Name Address Mobile
2 1 Kiran Bengaluru, 99999 99999
3 Mysore Road
4 6th Lane
5 2 John Mandya 77777 77777
6 Taluka Junction
7 3 Ravi Mysore 88888 88888
How can i convert this into a proper df? I tried filtering out the lines that start with a digit by using regex but after that I got stuck. I need to gather address lines (that have no number at the beginning) and attach them to the previous address text and then split lines into columns. I tried splitting based the space between id, name, address and Mobile but it is not constant across all lines. How can I resolve this issue? Thanks in advance.
Edit
As suggested, I tried pdf_data and i got a table (head(15)) like this with x and y positions of the text
# A tibble: 15 x 6
width height x y space text
<int> <int> <int> <int> <lgl> <chr>
1 8 11 77 74 FALSE Id
2 5 11 77 88 FALSE 1
3 26 11 181 74 FALSE Name
4 23 11 181 88 FALSE Kiran
5 5 11 77 129 FALSE 2
6 20 11 181 129 FALSE John
7 5 11 77 156 FALSE 3
8 18 11 181 156 FALSE Ravi
9 35 11 294 74 FALSE Address
10 48 11 294 88 FALSE Bengaluru,
11 33 11 294 102 TRUE Mysore
12 22 11 330 102 FALSE Road
13 5 11 294 115 FALSE 6
14 5 6 299 114 TRUE th
15 21 11 308 115 FALSE Lane
based on this table I can filter out the x values and get the columns as vectors. but if there are spaces in the values( like address) this filtering will not work. Is there a way to gather address column based on x and y values?
Basically I need to gather rows based on a value (ex: x == 294) until the same value appears then I can use str_c to merge those cells to a single string.
CodePudding user response:
based on your first method, try this function after getting row_df :
library(dplyr)
parse_pdfs_lines_ById<- function(raw_df){
# ----delete rownames : the first character and space
raw_df=raw_df%>%
mutate(rawline=sub('.', '', rawline))%>%
# ----remove the first space to keep Id as a first word
mutate(rawline=gsub('^ ', '', rawline))
# ------ now ignore the raw of colnames
raw_df=data.frame(rawline=raw_df[-1,])
# ---------assign the correct id to correct line
# id=""
# initialize index of line
i=1
while (i<nrow(raw_df))
{
if(grepl("^[0-9]",raw_df$rawline[i]))
{
# get the id , first word of line ./!\ not the first character! e.g : id == 22 )
id=stringr::word(raw_df$rawline[i],1)
}else{
raw_df$rawline[i]=paste0(id,raw_df$rawline[i])
}
i=i 1
}
# > raw_df
# rawline
# 1 Kiran Bengaluru, 99999 99999
# 1 Mysore Road
# 1 6th Lane
# 2 John Mandya 77777 77777
# 2 Taluka Junction
# 3 Ravi Mysore 88888 88888
# ------build the dataframe
col_df= list("Id","Name", "Address", "Mobile")
raw_df2 =setNames(data.frame(matrix(ncol = 4, nrow = 0),stringsAsFactors = F),col_df)
for (j in 1:nrow(raw_df))
{
# split the line of dataframe by double space or more
line= unlist(strsplit(raw_df$rawline[j]," "))
df_line= data.frame(t(line),stringsAsFactors = F)
# if all 4 column exist , affect column names else these is just Id and Part2 of adress ==>column Adress2
names(df_line) = unlist(ifelse(length(line)==4,
list(col_df),
list(c("Id","Adress2")))
)
# rbind even the number of column is not the same
raw_df2=plyr::rbind.fill(raw_df2,df_line )
}
# ----- clean final dataframe
final_df = raw_df2%>%
# replace Na with emty value
mutate_all(~ifelse(is.na(.), "", .))%>%
group_by(Id)%>%
mutate(Address= paste(Address,Adress2,collapse = " "))%>% #put collapse ="\r\n" to display the exact format
# keep just the first line by Id
slice(1)%>%
# remove adress2 column
select(-Adress2)%>%
ungroup()
return(final_df)
}
apply function on your first example and the result is :
raw_df = data.frame(rawline=
c("1 Id Name Address Mobile",
"2 1 Kiran Bengaluru, 99999 99999",
"3 Mysore Road",
"4 6th Lane",
"5 2 John Mandya 77777 77777",
"6 Taluka Junction",
"7 3 Ravi Mysore 88888 88888")
)
final_df=parse_pdfs_lines_ById(raw_df)
final_df
# final_df
# A tibble: 3 x 4
# Id Name Address Mobile
# <chr> <chr> <chr> <chr>
# 1 Kiran "Bengaluru, Mysore Road 6th Lane" 99999 99999
# 2 John "Mandya Taluka Junction" 77777 77777
# 3 Ravi "Mysore " 88888 88888
hope this will help!, please let me know if something does not work or is not clear enough.(update response format).