I have a rather messy dataframe in which I need to assign first 3 rows as a multilevel column names.
This is my dataframe and I need index 3, 4 and 5 to be my multiindex column names.
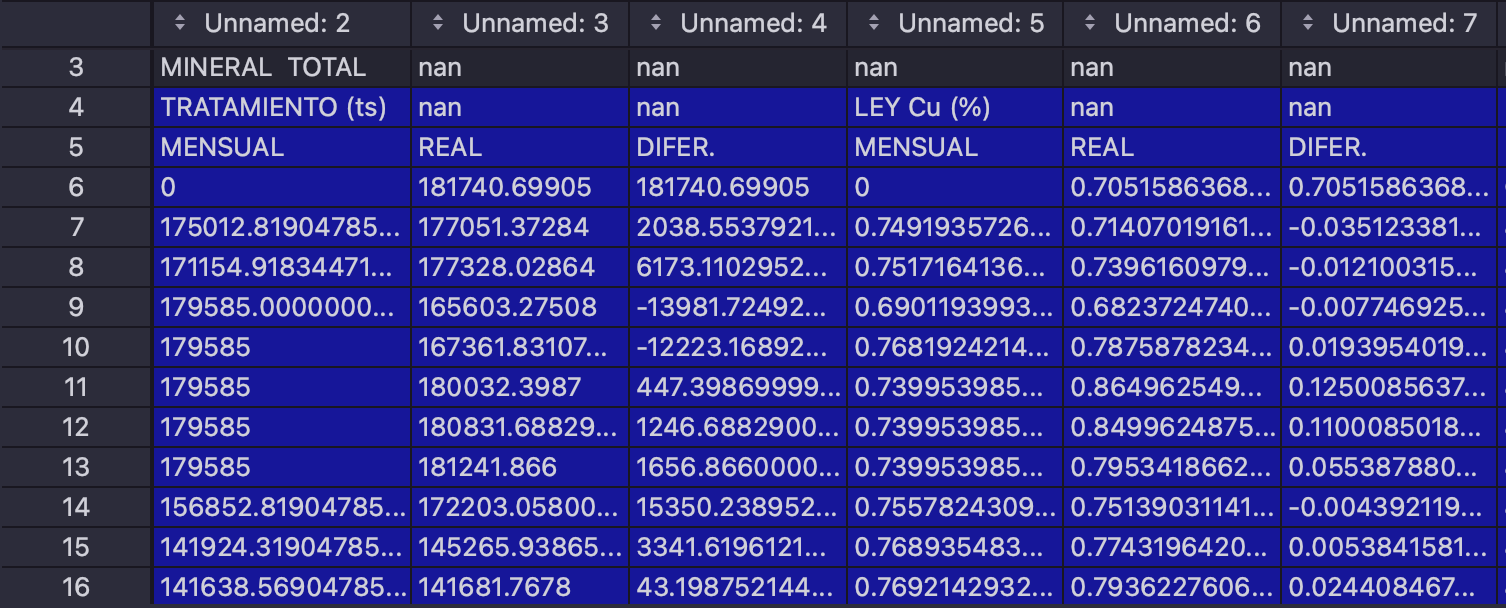
For example, 'MINERAL TOTAL' should be the level 0 until next item; 'TRATAMIENTO (ts)' should be level 1 until 'LEY Cu(%)' comes up.
What I need actually is try to emulate what pandas.read_excel does when 'header' is specified with multiple rows.
Please help!
I am trying this, but no luck at all:
pd.DataFrame(data=df.iloc[3:, :].to_numpy(), columns=tuple(df.iloc[:3, :].to_numpy(dtype='str')))
CodePudding user response:
You can pass a list of row indexes to the header argument and pandas will combine them into a MultiIndex.
import pandas as pd
df = pd.read_excel('ExcelFile.xlsx', header=[0,1,2])
By default, pandas will read in the top row as the sole header row. You can pass the header argument into pandas.read_excel() that indicates how many rows are to be used as headers. This can be either an int, or list of ints. See the pandas.read_excel() documentation for more information.
As you mentioned you are unable to use pandas.read_excel(). However, if you do already have a DataFrame of the data you need, you can use pandas.MultiIndex.from_arrays(). First you would need to specify an array of the header rows which in your case would look something like:
array = [df.iloc[0].values, df.iloc[1].values, df.iloc[2].values]
df.columns = pd.MultiIndex.from_arrays(array)
The only issue here is this includes the "NaN" values in the new MultiIndex header. To get around this, you could create some function to clean and forward fill the lists that make up the array.
Although not the prettiest, nor the most efficient, this could look something like the following (off the top of my head):
import numpy as np
def forward_fill(iterable):
return pd.Series(iterable).ffill().to_list()
zero = forward_fill(df.iloc[0].to_list())
one = forward_fill(df.iloc[1].to_list())
two = one = forward_fill(df.iloc[2].to_list())
array = [zero, one, two]
df.columns = pd.MultiIndex.from_arrays(array)
You may also wish to drop the header rows (in this case rows 0 and 1) and reindex the DataFrame.
df.drop(index=[0,1,2], inplace=True)
df.reset_index(drop=True, inplace=True)
CodePudding user response:
Since columns are also indices, you can just transpose, set index levels, and transpose back.
df.T.fillna(method='ffill').set_index([3, 4, 5]).T