I have connected to a REST API and the data is structured in a nested JSON format that requires some transformation before I can insert into a SQL table. I am trying to use Azure Data Factory to facilitate the transformation, but I do not know how to trim off the unnecessary data. This is what it looks like:
{
"count": 216,
"results": [
{
"key": "users",
"id": "18603444"
},
{
"key": "users",
"id": "18603297"
},
{
"key": "users",
"id": "18603298"
},
{
"key": "users",
"id": "18603445"
},
{
"key": "users",
"id": "16407315"
},
{
"key": "users",
"id": "18636176"
},
{
"key": "users",
"id": "18588630"
},
{
"key": "users",
"id": "18588941"
},
{
"key": "users",
"id": "18603301"
},
{
"key": "users",
"id": "18603302"
},
{
"key": "users",
"id": "18603303"
},
{
"key": "users",
"id": "18588634"
},
{
"key": "users",
"id": "18722305"
},
{
"key": "users",
"id": "18603446"
},
{
"key": "users",
"id": "18604710"
},
{
"key": "users",
"id": "18624916"
},
{
"key": "users",
"id": "18625925"
},
{
"key": "users",
"id": "18603447"
},
{
"key": "users",
"id": "18603448"
},
{
"key": "users",
"id": "18603305"
}
],
"users": {
"18603444": {
"full_name": "",
"photo_path": "",
"email_address": "",
"headline": "",
"generic": false,
"disabled": false,
"update_whitelist": [
"full_name",
"headline",
"email_address",
"external_reference",
"linkedin_url",
"bio",
"website",
"company_name",
"address1",
"address2",
"city",
"state",
"zip"
],
"account_id": "",
"id": "18603444"
},
"meta": {
"count": 216,
"page_count": 11,
"page_number": 1,
"page_size": 20
}}
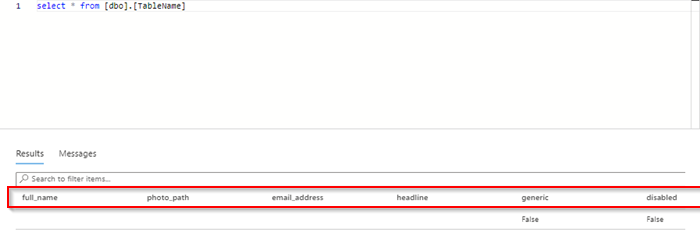
Each user is structured with their ID and their respective data. I want to remove the first part with the count and results and the last part with the meta and ONLY keep the data in each ID object. I think i can delete those two pieces in the mapping of the Copy into step, but I am not sure the best practice.
How do I do this with Azure Data Factory and SQL? Or should I use an Azure Function? I am not allowed to use python or any other scripting (if it is possible). Can someone please assist?
CodePudding user response:
Add a data flow activity to your pipeline. In the data flow, add a REST source and then a Select transformation. In the Select transformation, there is a mapping panel. In there, remove the JSON properties you wish to discard.
CodePudding user response:
Here is the sample procedure for the transformation of Nested JSON to SQL DB
Create a linked service to the REST API.
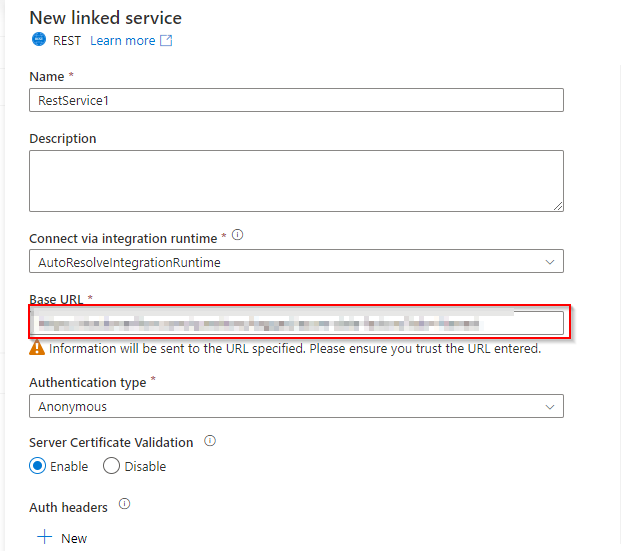
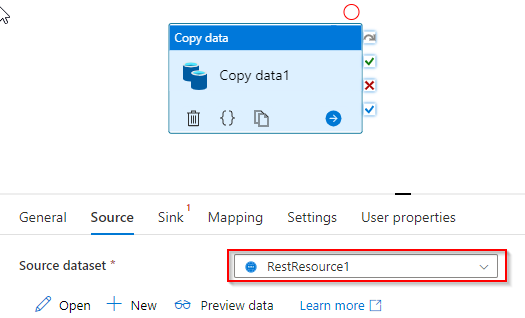
Attched dataset as the source in Copy activity.
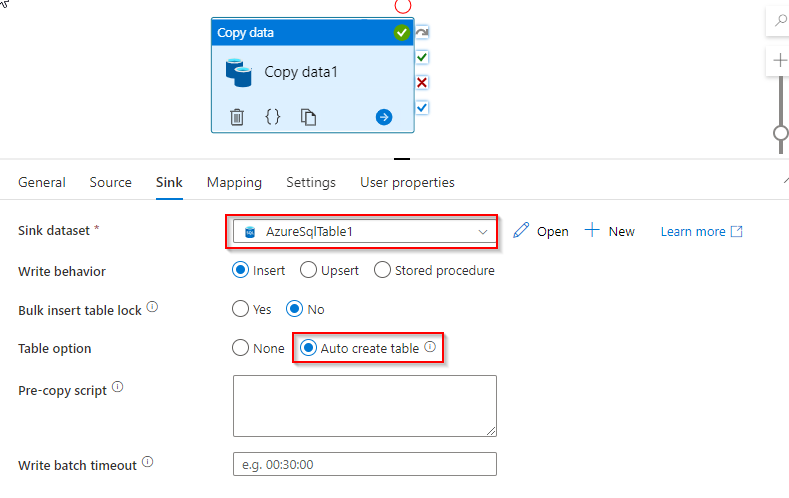
Create Linked Service to SQL DB as sink.
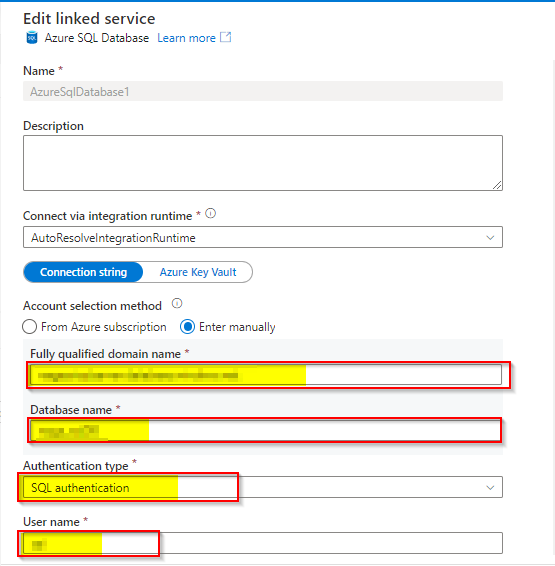
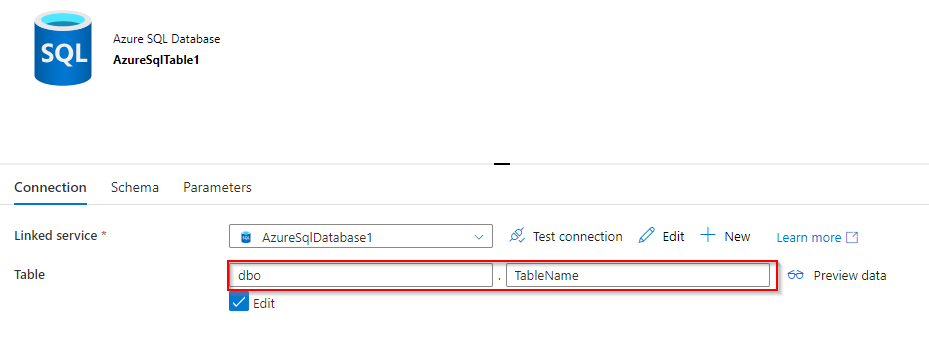
Dataset of SQL database attached at the sink to copy activity.
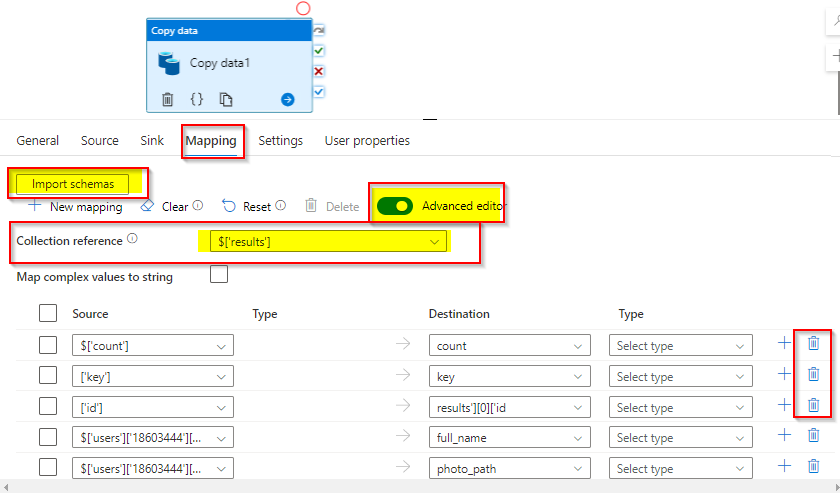
In the Mapping, Import the schema from the data remove the unnecessary fields by selecting and delete the columns.
Result we get as per the expected in SQL DB with required data from the Nested JSON.