I have json data which is in the structure below:
{"Text1": 4, "Text2": 1, "TextN": 123}
I want to read the json file and make a dataframe such as
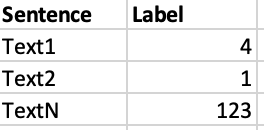
Each key value pairs will be a row in the dataframe and I need to need headers "Sentence" and "Label". I tried with using lines = True but it returns all the key-value pairs in one row.
data_df = pd.read_json(PATH_TO_DATA, lines = True)
What is the correct way to load such json data?
CodePudding user response:
you can use:
with open('json_example.json') as json_data:
data = json.load(json_data)
df=pd.DataFrame.from_dict(data,orient='index').reset_index().rename(columns={'index':'Sentence',0:'Label'})
CodePudding user response:
Easy way that I remember
import pandas as pd
import json
with open("./data.json", "r") as f:
data = json.load(f)
df = pd.DataFrame({"Sentence": data.keys(), "Label": data.values()})
With read_json
To read straight from the file using read_json, you can use something like:
pd.read_json("./data.json", lines=True)\
.T\
.reset_index()\
.rename(columns={"index": "Sentence", 0: "Labels"})
Explanation
A little dirty but as you probably noticed, lines=True isn't completely sufficient so the above transposes the result so that you have
| (index) | 0 |
|---|---|
| Text1 | 4 |
| Text2 | 1 |
| TextN | 123 |
So then resetting the index moves the index over to be a column named "index" and then renaming the columns.