I have two sets of data that I will be evaluating against one another. A heavily reduced example looks like this:
library(dplyr)
library(tidyverse)
library(sqldf)
library(dbplyr)
library(httr)
library(purrr)
library(jsonlite)
library(magrittr)
library(tidyr)
library(tidytext)
people_records_ex <- structure(list(id = c(123L, 456L, 789L), name = c("Anna Wilson",
"Jeff Smith", "Craig Mills"), biography = c("Student at Ohio State University. Class of 2024.",
"Second year law student at Stanford. Undergrad at William & Mary",
"University of North Texas Volleyball!")), class = "data.frame", row.names = c(NA,
-3L))
college_records_ex <- structure(list(college_id = c(234L, 567L, 891L, 345L), college_name = c("Ohio State University",
"Stanford", "William & Mary", "University of North Texas"), college_city = c("Columbus",
"Stanford", "Williamsburg", "Denton"), college_state = c("OH",
"CA", "VA", "TX")), class = "data.frame", row.names = c(NA, -4L
))
I am trying to create a match against the contents of the biography text string in people_records_ex against college_name in college_records_ex so the final output will look like this:
final_records_ex <- structure(list(id = c(123L, 456L, 456L, 789L), name = c("Anna Wilson",
"Jeff Smith", "Jeff Smith", "Craig Mills"), college_name = c("Ohio State University",
"Stanford", "William & Mary", "University of North Texas"), college_city = c("Columbus",
"Stanford", "Williamsburg", "Denton"), college_state = c("OH",
"CA", "VA", "TX")), class = "data.frame", row.names = c(NA, -4L
))
Or to provide a more visual example of the final output I'm expecting:
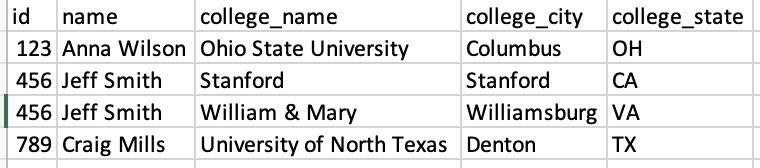
But when I run the following code, it produces zero results, which is not correct:
college_extract <- people_records_ex %>%
left_join(college_records_ex, by = c("biography" = "college_name")) %>%
filter(!is.na(college_state)) %>% dplyr::select(id, name, college_name, college_city, college_state) %>% distinct()
What am I doing incorrectly and what would the correct version look like?
CodePudding user response:
Here's a very tidy and straightforward solution with fuzzy_join:
library(fuzzyjoin)
library(stringr)
library(dplyr)
fuzzy_join(
people_records_ex, college_records_ex,
by = c("biography" = "college_name"),
match_fun = str_detect,
mode = "left"
) %>%
select(-biography)
id name college_id college_name college_city college_state
1 123 Anna Wilson 234 Ohio State University Columbus OH
2 456 Jeff Smith 567 Stanford Stanford CA
3 456 Jeff Smith 891 William & Mary Williamsburg VA
4 789 Craig Mills 345 University of North Texas Denton TX
CodePudding user response:
Assuming the college names in the biographies are spelled out exactly as they appear in the colleges table and the datasets are relatively small, all matches can be generated with a regex of all college names as follows
library(dplyr)
people_records_ex <- structure(list(id = c(123L, 456L, 789L), name = c(
"Anna Wilson",
"Jeff Smith", "Craig Mills"
), biography = c(
"Student at Ohio State University. Class of 2024.",
"Second year law student at Stanford. Undergrad at William & Mary",
"University of North Texas Volleyball!"
)), class = "data.frame", row.names = c(
NA,
-3L
)) %>% tibble::tibble()
college_records_ex <- structure(list(college_id = c(234L, 567L, 891L, 345L), college_name = c(
"Ohio State University",
"Stanford", "William & Mary", "University of North Texas"
), college_city = c(
"Columbus",
"Stanford", "Williamsburg", "Denton"
), college_state = c(
"OH",
"CA", "VA", "TX"
)), class = "data.frame", row.names = c(NA, -4L)) %>%
tibble::tibble()
# join college names in a regex pattern
colleges_regex <- paste0(college_records_ex$college_name, collapse = "|")
colleges_regex
#> [1] "Ohio State University|Stanford|William & Mary|University of North Texas"
# match all against bio, giving a list-column of matches
people_records_ex %>%
mutate(matches = stringr::str_match_all(biography, colleges_regex))
#> # A tibble: 3 × 4
#> id name biography matches
#> <int> <chr> <chr> <list>
#> 1 123 Anna Wilson Student at Ohio State University. Class of 2024. <chr[…]>
#> 2 456 Jeff Smith Second year law student at Stanford. Undergrad at … <chr[…]>
#> 3 789 Craig Mills University of North Texas Volleyball! <chr[…]>
# unnest the list column wider to give 1 row per person per match
people_records_ex %>%
mutate(matches = stringr::str_match_all(biography, colleges_regex)) %>%
tidyr::unnest_longer(matches)
#> # A tibble: 4 × 4
#> id name biography match…¹
#> <int> <chr> <chr> <chr>
#> 1 123 Anna Wilson Student at Ohio State University. Class of 2024. Ohio S…
#> 2 456 Jeff Smith Second year law student at Stanford. Undergrad at W… Stanfo…
#> 3 456 Jeff Smith Second year law student at Stanford. Undergrad at W… Willia…
#> 4 789 Craig Mills University of North Texas Volleyball! Univer…
#> # … with abbreviated variable name ¹matches[,1]
Created on 2022-10-26 with reprex v2.0.2
This may be joined back to the college table such that it is annotated with college info.
CodePudding user response:
In base R you can do:
do.call(rbind, lapply(college_records_ex$college_name,
\(x) people_records_ex[grep(x, people_records_ex$biography),1:2])) |>
cbind(college_records_ex[-1])
This does some matching and I subsetted the first two columns which are the id and name, cbinding it with the second data.frame getting rid of the first column
id name college_name college_city college_state
1 123 Anna Wilson Ohio State University Columbus OH
2 456 Jeff Smith Stanford Stanford CA
21 456 Jeff Smith William & Mary Williamsburg VA
3 789 Craig Mills University of North Texas Denton TX