I'm writing a text formatter that needs to clear out special characters from Chinese pinyins and replace them with their latin counterparts. But I've suddenly stumbled upon this problem So, let's say I have this syllable
shu
I need to check if it contains one letter of the list below:
üǖǘǚǚü̆ǜ
I have a RegExp like this
[üǖǘǚǚü̆ǜ]{1}
It shouldn't match simple "u" but it does.
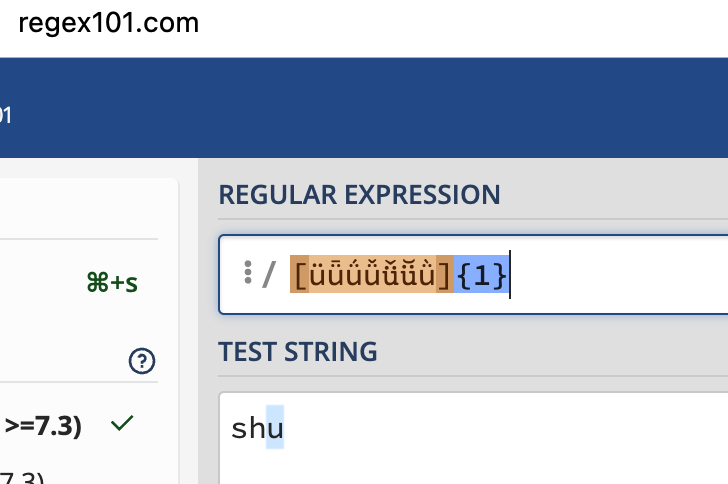
How can I get around this?
CodePudding user response:
Most of those graphemes consist of multiple code points, one of which is the letter 'u'. A character class in Unicode-aware regex engines is a class of code points, not graphemes, so this character class will match any of the code points contained within it, including the letter 'u'.
As far as I'm aware no regex engine provides anything like a "grapheme class", so your only option is an alternation (i.e. ü|ǖ|ǘ|...).
PS: {1} is redundant.
CodePudding user response:
Try to use non-capturing group with each character separately:
(?:ü|ǖ|ǘ|ǚ|ǚ|ü̆|ǜ){1}
Seems working.
CodePudding user response:
It Seems that some special u letters you're using includes the u matching. I've found this workaround:
[üǖǘǚǚü̆ǜ](?<!u)
Using a negative lookbehind that doesn't match the normal "u" letter.
Link to test: https://regex101.com/r/U1N2Z9/1