I have this DataFrame.
High Close
Close Time
2022-10-23 21:41:59.999 19466.02 19461.29
2022-10-23 21:42:59.999 19462.48 19457.83
2022-10-23 21:43:59.999 19463.13 19460.09
2022-10-23 21:44:59.999 19465.15 19463.76
I'm attempting to check if Close at a later date (up to 600 rows later but no more) goes above the close of an earlier date & High is lower than the High of the same earlier date then I want to get the location of both the earlier and later date and make new columns in the Dataframe with those locations.
Expected output:
High Close LC HC HH LH
Close Time
2022-10-23 21:41:59.999 19466.02 19461.29 19461.29 NaN 19466.02 NaN
2022-10-23 21:42:59.999 19462.48 19457.83 NaN NaN NaN NaN
2022-10-23 21:43:59.999 19463.13 19460.09 NaN NaN NaN NaN
2022-10-23 21:44:59.999 19465.15 19463.76 NaN 19463.76 NaN 19465.15
This is the code I have tried
# Checking if conditions are met
for i in range(len(df)):
for a in range(i,600):
if (df.iloc[i:, 1] < df.iloc[a, 1]) & (df.iloc[i:, 0] > df.iloc[a, 0]):
# Creating new DataFrame columns
df['LC'] = df.iloc[i, 1]
df['HC'] = df.get_loc[i,1]
df['HH'] = df.get_loc[a, 0]
df['LH'] = df.get_loc[a, 0]
else:
continue
This line: if (df.iloc[i:, 1] < df.iloc[a, 1]) & (df.iloc[i:, 0] > df.iloc[a, 0]):
Is causing error: ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
I believe I should be using any() instead of an if statement but I am unsure of how to apply it. I also think that there many be an issue with the way I am using the df.get_loc[] but I am unsure. I'm a pandas beginner so if it is obvious I apologize
Here is an image to help visualise what I am attempting to do using a candlestick chart
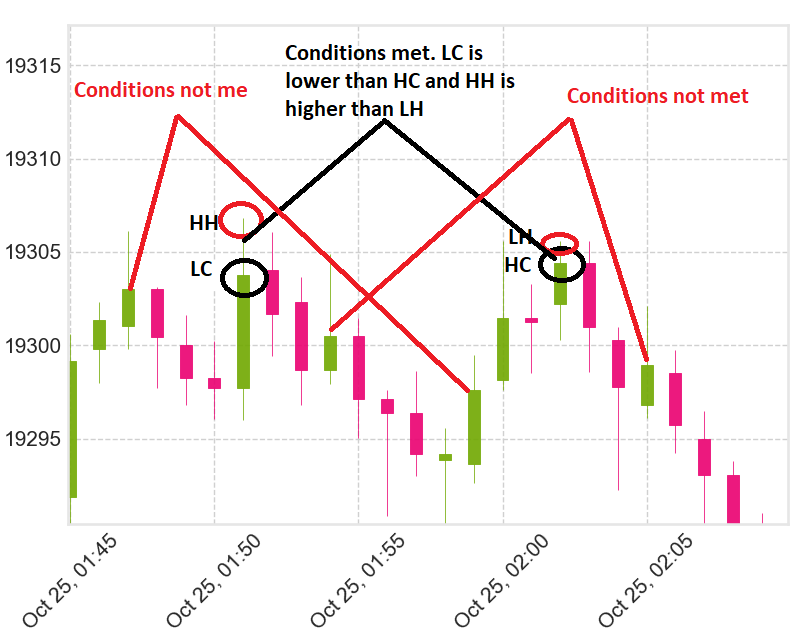
what I want to do is check if HC is higher than LC and LH is lower than HH then add that data to new columns in the DataFrame
Here is an additional way I tried to achieve the desired output
idx_close, idx_high = map(df.columns.get_loc, ["Close", "High"])
# Check Conditions
for i in range(len(df)):
bool_l = [((df.iloc[i, idx_close] < df.iloc[a, idx_close]) &
(df.iloc[i, idx_high] > df.iloc[a, idx_high])
).any() for a in range(i, 600)]
# Creating new DataFrame columns
df.loc[i, 'LC'] = df.iloc[i,1]
df.loc[bool_l, 'HC'] = df.iloc[bool_l, 1]
# Creating new DataFrame columns
df.loc[i, 'HH'] = df.iloc[i, 0]
df.loc[bool_l, 'LH'] = df.iloc[bool_l, 0]
And I get an error IndexError: Boolean index has wrong length: 600 instead of 2867
On the line df.loc[bool_l, 'HC'] = df.iloc[bool_l, 1]
I assume the error comes from the range(i,600) but I don't know how to get around it
CodePudding user response:
Using regular for loop to iterate over dataframe is slow, instead you should use pandas built-in methods for dataframe because they are much faster.
Series has a built-in method diff() that iterates over that series and compares every value to previous one. So you could get 2 new serieses that each has information whether the previous close was less than todays
# You need numpy for this, if already imported, ignore this line
import numpy as np
# Make series for close and high
close = df["Close"].diff()
high = df["High"].diff()
I think you want to have lower "high" value and higher "close" value but with this logic it doesn't generate desired output.
# Then create new columns
df['LC'] = np.where((close > 0) & (high < 0), np.NaN, df["Close"])
df['HC'] = np.where((close > 0) & (high < 0), np.NaN, df["High"])
df['HH'] = np.where((close > 0) & (high < 0), np.NaN, df["Close"])
df['LH'] = np.where((close > 0) & (high < 0), np.NaN, df["High"])
if you provide more infomation about what LC, HC, HH, LH are supposed to be, or provide more examples, I can help you get correct results.
CodePudding user response:
As mentioned by @Jimpsoni, the question is a little unclear in defining what you mean by LC, HC, HH and HL. I will use the below definitions to answer your question:
C_tis the close price on a given day,tH_tis the high price on a given dat,t
Then if I understand correctly, you want to check the following two conditions:
- close condition: is there a future close price in the next 600 days which is higher than the the current close price?
- high condition: is there a future high price in the next 600 days which is lower than the high price from today?
And then for each day t, you want to find the first day in the future where both the conditions above are satisfied simultaneously.
With this understanding, I sketch a solution below.
Part 1: Setting up sample data (do this in your question next time)
import pandas as pd
import numpy as np
np.random.seed(2022)
# make example data
close = np.sin(range(610)) 10
high = close np.random.rand(*close.shape)
close[2] = 100 # to ensure the close condition cannot be met
dates = pd.date_range(end='2022-06-30', periods=len(close))
# insert into pd.dataframe
df = pd.DataFrame(index=dates, data=np.array([close, high]).T, columns=['close',
'high'])
The sample dataframe looks like below:
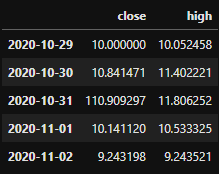
Part 2: Understand how to use rolling functions
Since at each point in time you want to subset your dataframe to a particular view in a rolling manner (always look 600 forward), it makes sense to use the built in .rolling method of pandas dataframes here. The .rolling() method is similar to a groupby in the sense that it allows you to iterate over different subsets of the dataframe, without explicitly writing the loop. rolling by default looks backwards, so we need to import a forward looking indexer to achieve the forward window. Note that you can also achieve the same forward window with some shifting, but it is less intuitive. The below chunk demonstrates how both methods give you the same result:
# create the rolling window object
# the simplest solution is to use the fixed size forward window as below
indexer = pd.api.indexers.FixedForwardWindowIndexer(window_size=600)
method_1 = df.rolling(indexer, min_periods=600).sum().dropna()
# can also achieve the same thing by doing the rolling computation and then shifting backward
method_2 = df.rolling(indexer, min_periods=600).sum().dropna(how='all')
# confirm they are the same
(method_1 == method_2).mean().mean() # output is 1.0 (all elements are equal)
Part 3: Write the logic that will be applied to each rolling view
Once we have the rolling frame, we can simply apply a function that will be applied to each rolling view of the dataframe. Here is the function, below will be some comments:
def check_conditions(ser, df_full):
df_chunk = df_full.loc[ser.index, :]
today_close, today_high = df_chunk.iloc[0,:2]
future_close_series, future_high_series = df_chunk.iloc[1:, 0], df_chunk.iloc[1:, 1]
close_condition = today_close < future_close_series
high_condition = today_high > future_high_series
both_condition = close_condition & high_condition
if both_condition.sum() == 0:
return 1
first_date_satisfied = future_close_series.index[np.where(both_condition)][0]
future_vals = df_chunk.loc[first_date_satisfied, ['close','high']].values
df_full.loc[ser.index[0], ['Future_Close', 'Future_High', 'Future_Date']] = np.append(future_vals, first_date_satisfied)
return 1
Some comments: First, notice that the function takes two arguments, the first is a series, and the second is the full dataframe. Unfortunately, the .rolling() only acts on a single column / row at a time. This is in contrast to .groupby() which allows access to the full dataframe produced by each group. To get around this, I use a pattern proposed in 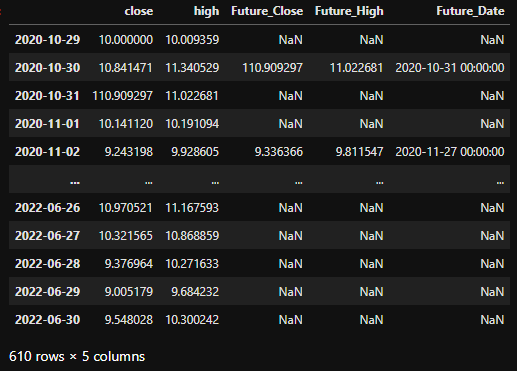
Hope it helps.