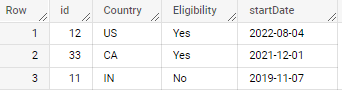
I have data in the form of key value pair (Not Json) as shown below
id | Attributes
---|---------------------------------------------------
12 | Country:US, Eligibility:Yes, startDate:2022-08-04
33 | Country:CA, Eligibility:Yes, startDate:2021-12-01
11 | Country:IN, Eligibility:No, startDate:2019-11-07
I would like to extract only startDate from Attributes section
Expected Output:
id | Attributes_startDate
---|----------------------
12 | 2022-08-04
33 | 2021-12-01
11 | 2019-11-07
One way that I tried was, I tired converting the Attributes column in the Input data into JSON by appending {, } at start and end positions respectively. Also some how tried adding double quotes on the Key values and tried extracting startDate. But, is there any other effective solution to extract startDate as I don't want to rely on Regex.
CodePudding user response:
is there any other effective solution to extract startDate as I don't want to rely on Regex.
If your feeling about Regex here really very strong - use below
select id, split(Attribute, ':')[safe_offset(1)] Attributes_startDate
from your_table, unnest(split(Attributes)) Attribute
where trim(split(Attribute, ':')[offset(0)]) = 'startDate'
CodePudding user response:
Use below (I think using RegEx here is the most efficient option)
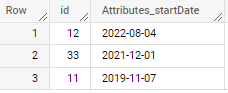
select id, regexp_extract(Attributes, r'startDate:(\d{4}-\d{2}-\d{2})') Attributes_startDate
from your_table
if applied to sample data in your question - output is
CodePudding user response:
Is there any way to just specify the key and extract its respective value? (Just like the way we can extract values using keys in a JSON column using JSON_QUERY)
you can try below
create temp function fakejson_extract(json string, attribute string) as ((
select split(kv, ':')[safe_offset(1)]
from unnest(split(json)) kv
where trim(split(kv, ':')[offset(0)]) = attribute
));
select id,
fakejson_extract(Attributes, 'Country') as Country,
fakejson_extract(Attributes, 'Eligibility') as Eligibility,
fakejson_extract(Attributes, 'startDate') as startDate
from your_table
if applied to sample data in your question - output is