I have the below data frame
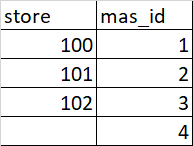
Now I want to transfer the data frame like below
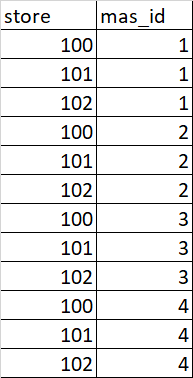
I have used the python commands to do that but none of them worked . Could anyone please help me with how to do that df.loc[df.index.repeat(df.mas_id)].reset_index(drop=True)
n_df = pd.concat([df] * final_n)
newdf = pd.DataFrame(np.repeat(df.values, final_n, axis=0))
CodePudding user response:
Use itertools library's function product
from itertools import product
combi_rows = product(df.store.dropna(), df.mas_id.dropna())
new_df = pd.DataFrame(combi_rows, columns=df.columns)
Output
store mas_id
0 100.0 1
1 100.0 2
2 100.0 3
3 100.0 4
4 101.0 1
5 101.0 2
6 101.0 3
7 101.0 4
8 102.0 1
9 102.0 2
10 102.0 3
11 102.0 4
Edit:
If you want to sort by mas_id column,
new_df = new_df.sort_values('mas_id')
Output
store mas_id
0 100.0 1
4 101.0 1
8 102.0 1
1 100.0 2
5 101.0 2
9 102.0 2
2 100.0 3
6 101.0 3
10 102.0 3
3 100.0 4
7 101.0 4
11 102.0 4
CodePudding user response:
You can the function product of itertools
import itertools
result = pd.DataFrame(list(itertools.product(df.store.unique(), df.mas_id.unique())),columns=df.columns)
and if you have nan values that you don't want to include just update it like this:
result = pd.DataFrame(list(itertools.product(df.store.dropna().unique(), df.mas_id.dropna().unique())),columns=df.columns)