I have dataframe
df1 = pd.DataFrame({'id': ['1','2','2','3','3','4','5'],
'event': ['Basket','Soccer','Soccer','Basket','Soccer','Basket','Soccer']})
I want to count unique values of event but exclude the repeated id. The result I expect are:
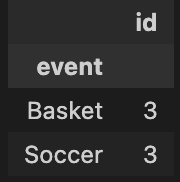
event count
Basket 3
Soccer 3
CodePudding user response:
This will work:
df1.groupby('event').agg({'id':lambda x: len(pd.unique(x))})
# OR
df1.groupby(['event']).agg(['nunique'])
Output:
CodePudding user response:
You can drop the duplicates in your dataframe usingthe function drop_duplicates:
df1 = df1.drop_duplicates()
Then, you simply need to group by event and use the count aggregation function:
df1 = df1.groupby("event").agg("count")