I'm trying to scrape data from that site 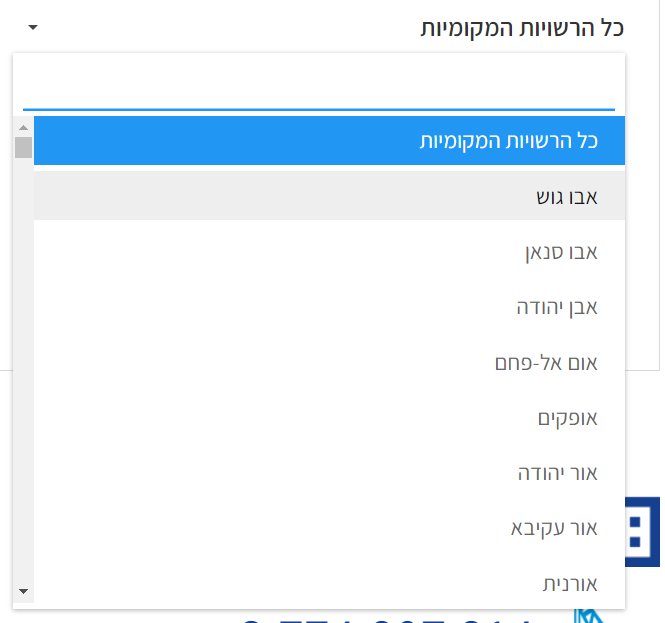
click on that button

and scrape these numbers
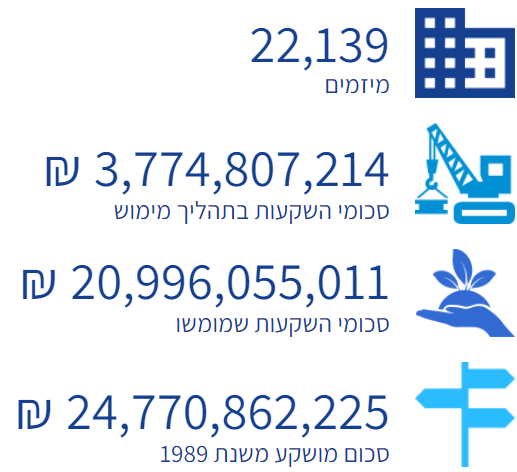
I do know how to scrape the numbers/ click or select buttons but I can't figure out how to iteratively select each option from that weird dropdown menu...
I do try to click on that button to open the dropdown menu as some suggestions over the internet but Unable to do so..:

button1 = driver.find_element_by_xpath('/html/body/form/div[3]/div[1]/div/div/div[1]/select')
but I get the error: Message: no such element: Unable to locate element
would love your help for a newbie in the field of web scrapping :)
CodePudding user response:
The data you need is loaded with js so you can use Selenium to get the list of cities. Here is one possible solution:
import csv
import requests
from typing import Union, Any
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_data(url: str, city_name: str) -> Union[dict[str, Any], str]:
payload = {
'city': city_name,
'mainCategory': 'בחר תחום',
'secondCategory': 'בחר תת תחום'
}
headers = {
'User-Agent': 'Mozilla/5.0'
}
try:
r = requests.post(url, data=payload, headers=headers).json()
return {
"City Name": city_name,
"Ventures": r[0],
"Realizable Investments": r[1],
"Realized Investments": r[2],
"Amount Invested Since 1989": r[3]
}
except ValueError:
return f'No data for {city_name}'
def save_to_csv(data: list) -> None:
with open(file='pais.csv', mode='a', encoding="utf-8") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow([*data])
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_experimental_option("excludeSwitches", ["enable-automation", "enable-logging"])
service = Service(executable_path="path/to/your/chromedriver.exe")
driver = webdriver.Chrome(service=service, options=options)
wait = WebDriverWait(driver, 15)
main_url = 'https://www.pais.co.il/info/Thank-to.aspx'
post_call_url = 'https://www.pais.co.il/grants/grantsRequestNumbers.ashx'
driver.get(main_url)
wait.until(EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe")))
cities = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#FacilitiesStats_ddlcity>option')))
city_names = [city.text for city in cities[1:]]
for name in city_names:
data = get_data(post_call_url, name)
if isinstance(data, dict):
save_to_csv(data.values())
else:
print(data)
driver.quit
For some cities there is no data for example: "בוסתאן אל-מרג" so we just print to the console No data for בוסתאן אל-מרג
Output csv file pais.csv:
אבו גוש,19,6117232,14813422,20930654
אבו סנאן,29,6517560,16225629,22743189
אבן יהודה,28,3945008,13107701,17052709
אום אל-פחם,76,56738614,200980004,257718618
אופקים,109,21988456,130339851,152328307
Tested on Python 3.9.10. Used Selenium 4.5.0 and requests 2.28.1
Of course, we can get the required data using only Selenium without using the requests library. But after testing this solution, it seemed to me faster. Since when making post request we immediately get the value we need, while to receive data using Selenium from the tag(div.counter) we must wait for the counter animation to complete
You can also use for example ThreadPoolExecutor then the process of getting and saving data will be much faster.
Here is one possible solution:
import csv
import requests
from itertools import repeat
from typing import Union, Any
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from concurrent.futures import ThreadPoolExecutor
def get_data(url: str, city_name: str) -> Union[dict[str, Any], str]:
payload = {
'city': city_name,
'mainCategory': 'בחר תחום',
'secondCategory': 'בחר תת תחום'
}
headers = {
'User-Agent': 'Mozilla/5.0'
}
try:
r = requests.post(url, data=payload, headers=headers).json()
return {
"City Name": city_name,
"Ventures": r[0],
"Realizable Investments": r[1],
"Realized Investments": r[2],
"Amount Invested Since 1989": r[3]
}
except ValueError:
return f'No data for {city_name}'
def save_to_csv(data: Union[dict, str]) -> None:
if isinstance(data, dict):
with open(file='pais.csv', mode='a', encoding="utf-8") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow([*data.values()])
else:
print(data)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_experimental_option("excludeSwitches", ["enable-automation", "enable-logging"])
service = Service(executable_path="path/to/your/chromedriver.exe")
driver = webdriver.Chrome(service=service, options=options)
wait = WebDriverWait(driver, 15)
main_url = 'https://www.pais.co.il/info/Thank-to.aspx'
post_call_url = 'https://www.pais.co.il/grants/grantsRequestNumbers.ashx'
driver.get(main_url)
wait.until(EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe")))
cities = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#FacilitiesStats_ddlcity>option')))
city_names = [city.text for city in cities[1:]]
with ThreadPoolExecutor() as executor:
data = executor.map(get_data, repeat(post_call_url), city_names)
executor.map(save_to_csv, data)
driver.quit