I 'm trying to pull data from website with beautifulsoap in python but the data confused me a bit and I don't quite understand how to do it. What I want to do is actually pull certain data. I just want to capture the title, examples ,meaning and origin data in the page, how can I do that?
I will share my own code but this is not correct code
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import pandas as pd
import json
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
url = "https://www.englishclub.com/ref/Idioms/"
mylist = [
"A",
"B",
"C",
"D",
"E",
"F",
"G",
"H",
"I",
"J",
"K",
"L",
"M",
"N",
"O",
"P",
"Q",
"R",
"S",
"T",
"U",
"V",
"W"
]
list = {}
idiomsUrls=[]
for i in range(23):
list[mylist[i]] = []
result = requests.get(url mylist[i] "/", headers = headers)
doc = BeautifulSoup(result.text, "html.parser")
idiomsUrls = doc.select('.linktitle a')
for tag in idiomsUrls:
result = requests.get(tag['href'])
doc = BeautifulSoup(result.text,"html.parser")
idioms = doc.select('main')
with open('idioms.json', 'w', encoding='utf-8') as f:
json.dump(list, f, ensure_ascii=False, indent=4)
I shared the screenshot of the data I want to capture.
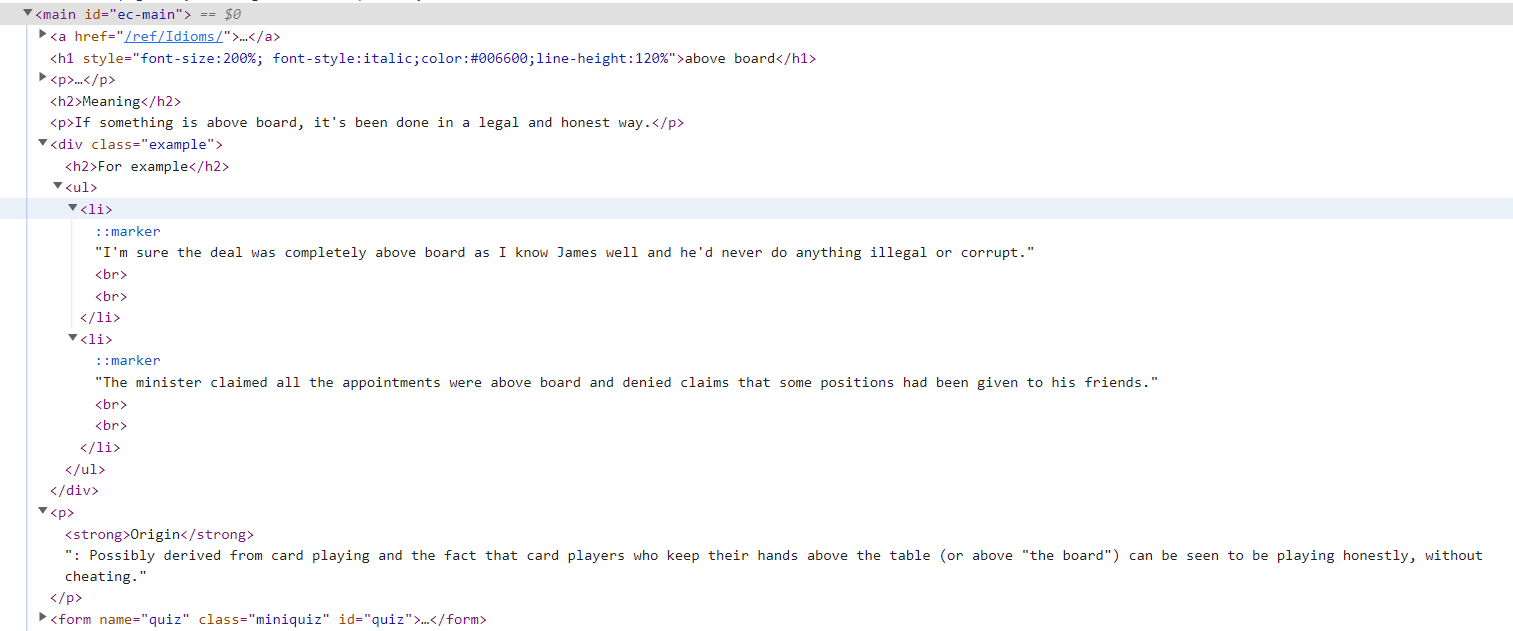
The data I want to capture here is the idiom title in the h1 tag, as an example, here is the above board, then the meaning and example section below it. examples There is also a part called origin at the bottom of the ul and li tags, I couldn't find how to shoot these parts.
CodePudding user response:
Try to keep it simple and select your elements more specific by tag, id or class and try to avoid using reserved keywords as variable names:
data = []
for i in mylist:
result = requests.get(url i "/", headers = headers)
doc = BeautifulSoup(result.text)
for tag in doc.select('.linktitle a'):
result = requests.get(tag['href'])
doc = BeautifulSoup(result.text)
data.append({
'idiom': doc.h1.get_text(strip=True),
'meaning': doc.select_one('h1 ~ h2 p').get_text(strip=True),
'examples':[e.get_text(strip=True) for e in doc.select('main ul li')]
})
Example
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
url = "https://www.englishclub.com/ref/Idioms/"
mylist = ["A"] #...
data = []
for i in mylist:
result = requests.get(url i "/", headers = headers)
doc = BeautifulSoup(result.text)
for tag in doc.select('.linktitle a'):
result = requests.get(tag['href'])
doc = BeautifulSoup(result.text)
data.append({
'idiom': doc.h1.get_text(strip=True),
'meaning': doc.select_one('h1 ~ h2 p').get_text(strip=True),
'examples':[e.get_text(strip=True) for e in doc.select('main ul li')]
})
data
Output
[{'idiom': 'above board',
'meaning': "If something is above board, it's been done in a legal and honest way.",
'examples': ["I'm sure the deal was completely above board as I know James well and he'd never do anything illegal or corrupt.",
'The minister claimed all the appointments were above board and denied claims that some positions had been given to his friends.']},
{'idiom': 'above the law',
'meaning': 'If someone is above the law, they are not subject to the laws of a society.',
'examples': ["Just because his father is a rich and powerful man, he seems to think he's above the law and he can do whatever he likes.",
'In a democracy, no-one is above the law - not even a president or a prime-minister.']},
{'idiom': "Achilles' heel",
'meaning': "An Achilles' heel is a weakness that could result in failure.",
'examples': ["He's a good golfer, but his Achilles' heel is his putting and it's often made him lose matches.",
"The country's dependence on imported oil could prove to be its Achilles' heel if prices keep on rising."]},...]