My goal is to get this price text (2078--as shown in the pic), it works with find_element but the values in the output would be the same across the loop.
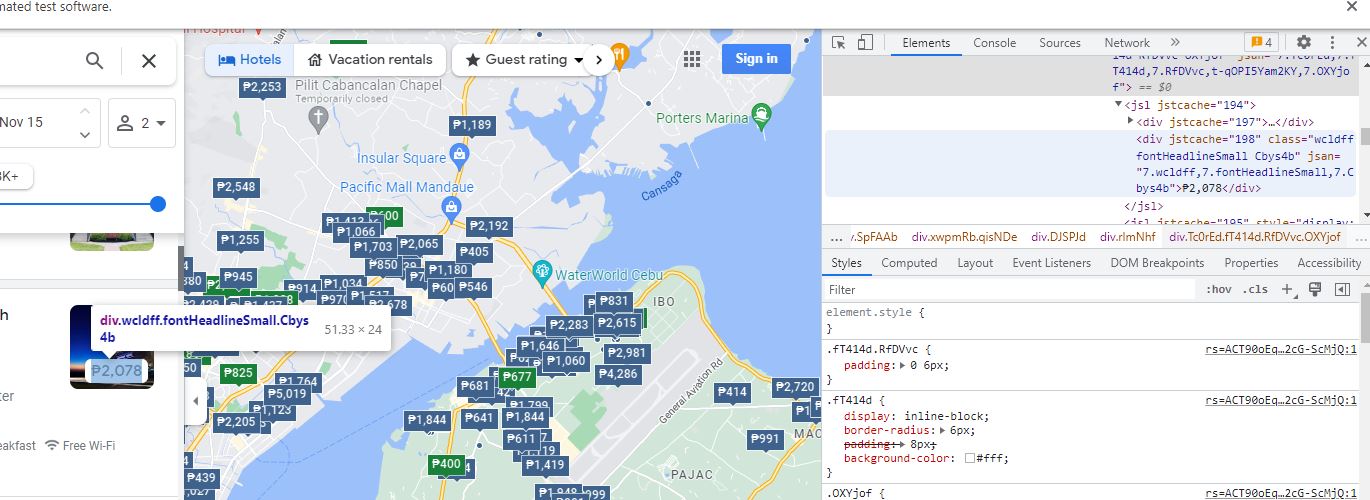
heres my code:
#Extracting the information from the results
for entry in entries:
#Empty list
labels=[]
#Extracting the Name, adress, Phone, and website:
name= entry.get_attribute("aria-label")
adress = entry.find_element(By.XPATH, '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[3]/div[1]/div[5]/div/div[2]/div[2]/div[3]/div/div[2]/div/div/jsl[1]/div[2]')
adress_get = adress.get_attribute('innerHTML')
phone = entry.find_elements(By.CLASS_NAME, 'xwpmRb.qisNDe').text
try:
webcontainer= entry.find_elements(By.CLASS_NAME, 'W4Efsd')
website="Hello"
except NoSuchElementException:
website="No website could be found"
print (name)
print (adress_get)
print (phone)
print (website)
My goal is to get list prices text from google map page (Web Scraping).
CodePudding user response:
use this xpath: //div[contains(@class,'wcldff fontHeadlineSmall Cbys4b')] NOT this: /html/body/div[3]/div[9]/div[9]/div/div/div[1]/div[2]/div/div[1]/div/div/div[3]/div[1]/div[5]/div/div[2]/div[2]/div[3]/div/div[2]/div/div/jsl[1]/div[2]
CodePudding user response:
To print all the texts of all the elements found by find_elements you need to do the following:
phones = entry.find_elements(By.CLASS_NAME, 'xwpmRb.qisNDe')
for phone in phones:
print(phone.text)
Or you can create a variable that holds elements' texts using this list comprehension:
phones = entry.find_elements(By.CLASS_NAME, 'xwpmRb.qisNDe')
phones_texts = [phone.text for phone in phones]
And then you can do whith it what you want, e.g. print the list or each element:
print(phones_texts)
# OR
for text in phones_texts:
print(text)