I'm learning multi-head attention with this article:
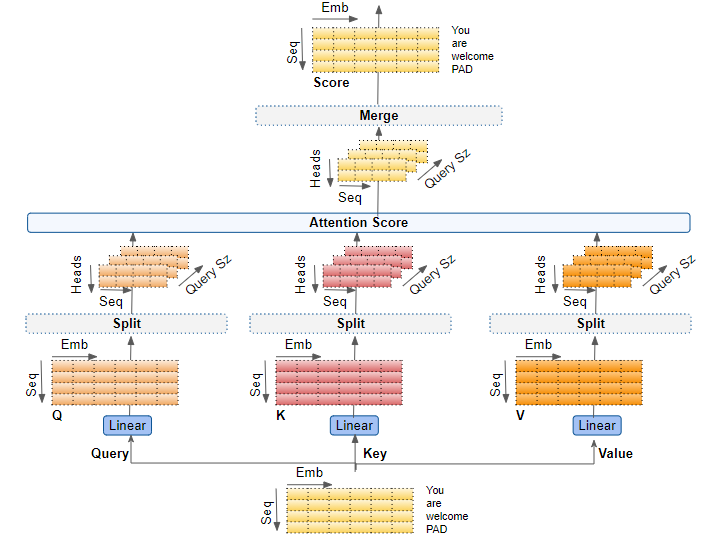
But MultiHeadAttention layer of Tensorflow seems to be more flexible:
https://www.tensorflow.org/api_docs/python/tf/keras/layers/MultiHeadAttention
- It does not require
key_dim * num_heads = embed_dim. Like:
layer = tf.keras.layers.MultiHeadAttention(num_heads = 2, key_dim = 4)
x = tf.keras.Input(shape=[3, 5])
layer(x, x)
# no error
Is the depth of the weight matrix in tf.MHA layer set to key_dim * num_heads regardless of embed_dim? So that Q/K/V can still be properly split by num_heads.
- However, the output depth of tf.MHA layer is (by default) guaranteed to be
embed_dim. So there is a final dense layer withembed_dimnodes to ensure the dimension?
CodePudding user response:
Yes, for 1 & 2. You can probe the weights by:
layer = tf.keras.layers.MultiHeadAttention(num_heads = 2, key_dim = 4, use_bias=False) #Set use_bias=False for simplicity.
x = tf.keras.Input(shape=[3, 5])
layer(x, x)
Get the weights associated,
weight_names = ['query', 'keys', 'values', 'proj']
for name, out in zip(weight_names,layer.get_weights()):
print(name, out.shape)
Output shapes:
query (5, 2, 4) # (embed_dim, num_heads, key_dim)
keys (5, 2, 4) # (embed_dim, num_heads, key_dim)
values (5, 2, 4) # (embed_dim, num_heads, value_dim/key_dim)
proj (2, 4, 5) # (num_heads, key_dim, embed_dim)
CodePudding user response:
In Multi-Head Attention, we split our input size according to the embedding dimensions. How's that? Let's take an example...
#Take an arbitrarily input of with embed_size = 512
x_embed = tf.random.normal((64,100,512))
Now, here if you want 8 heads in Multi-Head Attention. Then 512//8 your embed size 512 should be evenly divisible by a number of heads... why's that? because this will decide the dimensions of your every attention.
Number of heads = 8
embed size = 512
Attention Dims = embed_size//Number of heads
If your no of heads were not evenly divisible by embed_size then it will cause trouble making in reshaping! but how? let's look into that...
batch_dims = 64
no_of_heads = 8
seq_dims = 100
attn_dims = 64
tf.reshape(x (batch_dims, no_of_heads, seq_dims, attn_dims))
#After reshaping x shape would be
shape(64 , 8 , 100 , 64)
Important Note
tf.keras.layers.MultiHeadAttention() works the same your query may be different in seq_length from key and value but their embedding dimensions must be the same for all..