I'm using Oracle and SQL Developer. I have downloaded HR schema and need to do some queries with it. Now I'm working with table Employees. As an user I need to see employees with the highest gap between their salary and the average salary of all later hired colleagues in corresponding department. It seems quite interesting and really complicated. I have read some documentation and tried, for example LEAD(), that provides access to more than one row of a table at the same time:
SELECT
employee_id,
first_name
|| ' '
|| last_name,
department_id,
salary,
hire_date,
LEAD(hire_date)
OVER(PARTITION BY department_id
ORDER BY
hire_date DESC
) AS Prev_hiredate
FROM
employees
ORDER BY
department_id,
hire_date;
That shows for every person in department hiredate of later hired person. Also I have tried to use window clause to understand its concepts:
SELECT
employee_id,
first_name
|| ' '
|| last_name,
department_id,
hire_date,
salary,
AVG(salary)
OVER(PARTITION BY department_id
ORDER BY
hire_date ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING
) AS avg_sal
FROM
employees
ORDER BY
department_id,
hire_date;
The result of this query will be: 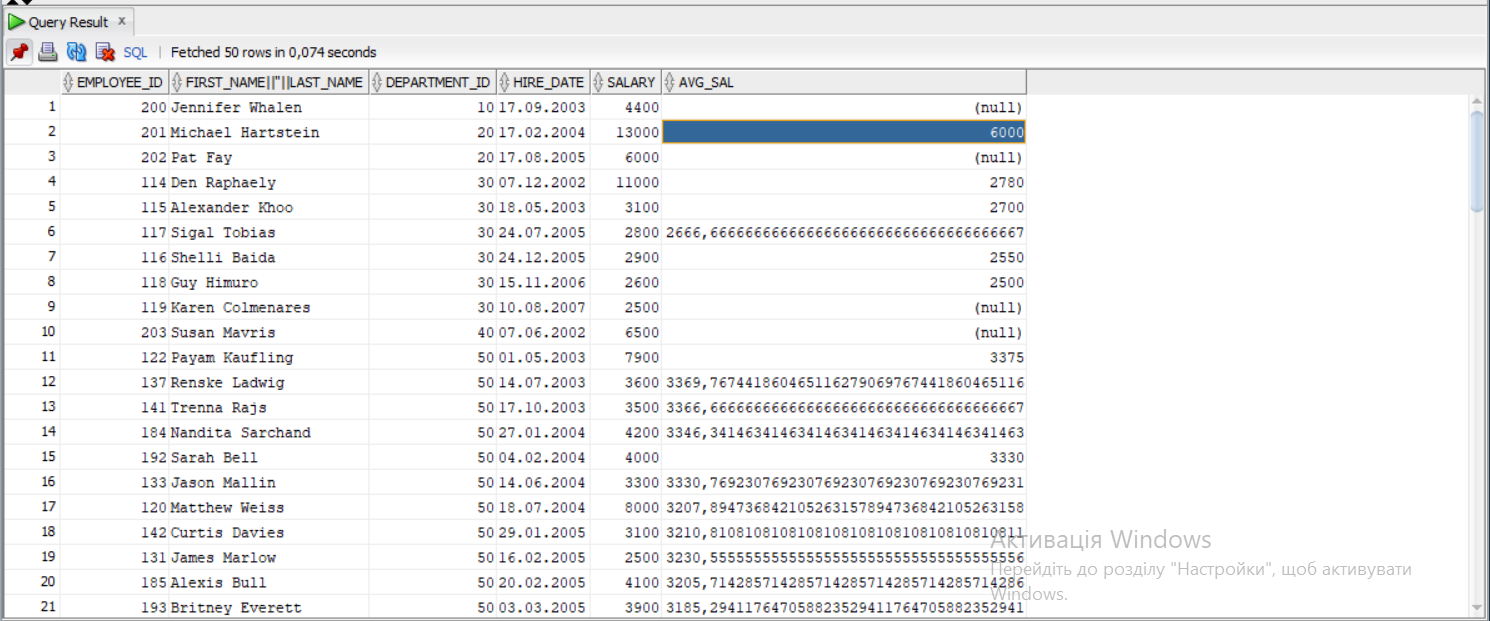
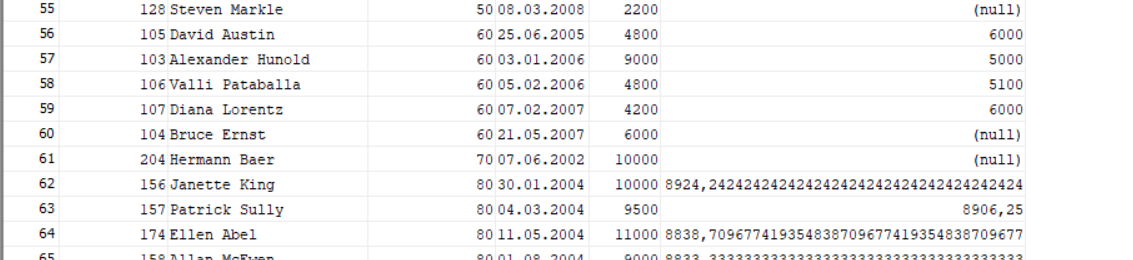
However, it is not exactly what I need. I need to reduce the result just by adding column with gap (salary-avr_sal), where the gap will be highest and receive one employee per department. How should the result look like: for example, we have 60 department. We have 5 employees there ordering by hire_date. First has salary 4800, second – 9000, third – 4800, fourth – 4200, fifth – 6000. If we do calculations: 4800 - ((9000 4800 4200 6000)/4)=-1200, 9000-((4800 4200 6000)/3)=4000, 4800 -((4200 6000)/2)=-300, 4200 - 6000=-1800 and the last person in department will have the highest gap: 6000 - 0 = 6000. Let's take a look on 20 department. We have two people there: first has salary 13000, second – 6000. Calculations: 13000 - 6000 = 7000, 6000 - 0 = 6000. The highest gap will be for first person. So for department 20 the result should be person with salary 13000, for department 60 the result should be person with salary 6000 and so on. How should look my query to get the appropriate result (what I need is marked bold up, also I want to see column with highest gap, can be different solutions with analytic functions, but should be necessarily included window clause)?
CodePudding user response:
You can get the average salary of employees that were hired prior to the current employee by just adapting the rows clause of your avg:
AVG(salary) OVER(
PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS avg_salary
The 1 PRECEDING clause tells the database not to include the current row in the window.
If you are looking for the employees with the greatest gap to that average, we can just order by the resultset:
SELECT e.*,
AVG(salary) OVER(
PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS avg_salary
FROM employees e
ORDER BY ABS(salary - avg_salary) DESC;
Finally, if you want the top "outlier salary" per department, then we need at least one more level. The shortest way to express this probably is to use ROW_NUMBER() to rank employees in each department by their salary gap to the average, and then to fetch all top rows per group using WITH TIES:
SELECT *
FROM (
SELECT e.*,
AVG(salary) OVER(
PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS avg_salary
FROM employees e
) e
ORDER BY ROW_NUMBER() OVER(
PARTITION BY department_id
ORDER BY ABS(salary - avg_salary) DESC
)
FETCH FIRST ROW WITH TIES
CodePudding user response:
Maybe this is what you are looking for.
Sample data:
WITH
emp (ID, EMP_NAME, HIRE_DATE, SALARY, DEPT) AS
(
Select 601, 'HILLER', To_Date('23-JAN-82', 'dd-MON-yy'), 4800, 60 From Dual Union All
Select 602, 'MILLER', To_Date('23-FEB-82', 'dd-MON-yy'), 9000, 60 From Dual Union All
Select 603, 'SMITH', To_Date('23-MAR-82', 'dd-MON-yy'), 4800, 60 From Dual Union All
Select 604, 'FORD', To_Date('23-APR-82', 'dd-MON-yy'), 4200, 60 From Dual Union All
Select 605, 'KING', To_Date('23-MAY-82', 'dd-MON-yy'), 6000, 60 From Dual Union All
Select 201, 'SCOT', To_Date('23-MAR-82', 'dd-MON-yy'), 13000, 20 From Dual Union All
Select 202, 'JONES', To_Date('23-AUG-82', 'dd-MON-yy'), 6000, 20 From Dual
),
Create CTE named grid with several analytic functions and windowing clauses. They are not all needed but the resulting dataset below shows the logic with all components included.
grid AS
(
Select
g.*, Max(GAP) OVER(PARTITION BY DEPT) "DEPT_MAX_GAP"
From
(
Select
ROWNUM "RN",
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN Unbounded Preceding And Current Row) "RN_DEPT",
ID, EMP_NAME, HIRE_DATE, DEPT, SALARY,
--
Nvl(Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following), 0) "SUM_SAL_LATER",
Nvl(Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following), 0) "COUNT_EMP_LATER",
--
Nvl(Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following) /
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following), 0) "AVG_LATER",
--
SALARY -
Nvl((
Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following) /
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following)
), 0) "GAP"
from
emp
Order By
DEPT, HIRE_DATE, ID
) g
Order By
RN
)
CTE grid resultiing dataset:
| RN | RN_DEPT | ID | EMP_NAME | HIRE_DATE | DEPT | SALARY | SUM_SAL_LATER | COUNT_EMP_LATER | AVG_LATER | GAP | DEPT_MAX_GAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 601 | HILLER | 23-JAN-82 | 60 | 4800 | 24000 | 4 | 6000 | -1200 | 6000 |
| 2 | 2 | 602 | MILLER | 23-FEB-82 | 60 | 9000 | 15000 | 3 | 5000 | 4000 | 6000 |
| 3 | 3 | 603 | SMITH | 23-MAR-82 | 60 | 4800 | 10200 | 2 | 5100 | -300 | 6000 |
| 4 | 4 | 604 | FORD | 23-APR-82 | 60 | 4200 | 6000 | 1 | 6000 | -1800 | 6000 |
| 5 | 5 | 605 | KING | 23-MAY-82 | 60 | 6000 | 0 | 0 | 0 | 6000 | 6000 |
| 6 | 1 | 201 | SCOT | 23-MAR-82 | 20 | 13000 | 6000 | 1 | 6000 | 7000 | 7000 |
| 7 | 2 | 202 | JONES | 23-AUG-82 | 20 | 6000 | 0 | 0 | 0 | 6000 | 7000 |
Main SQL
SELECT
g.ID, g.EMP_NAME, g.HIRE_DATE, g.DEPT, g.SALARY, g.GAP
FROM
grid g
WHERE
g.GAP = g.DEPT_MAX_GAP
Order By
RN
Resulting as:
| ID | EMP_NAME | HIRE_DATE | DEPT | SALARY | GAP |
|---|---|---|---|---|---|
| 605 | KING | 23-MAY-82 | 60 | 6000 | 6000 |
| 201 | SCOT | 23-MAR-82 | 20 | 13000 | 7000 |
Without CTE and with all unnecessery columns excluded it looks like this:
SELECT ID, EMP_NAME, HIRE_DATE, DEPT, SALARY, GAP
FROM
(
( Select g.*, Max(GAP) OVER(PARTITION BY DEPT) "DEPT_MAX_GAP"
From( Select
ID, EMP_NAME, HIRE_DATE, DEPT, SALARY,
SALARY -
Nvl(( Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following) /
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following)
), 0) "GAP"
From emp
Order By DEPT, HIRE_DATE, ID
) g
)
)
WHERE GAP = DEPT_MAX_GAP
Order By DEPT, HIRE_DATE, ID
It seems like this is all you need.
Regards...