train.loc[:,'nd_mean_2021-04-15':'nd_mean_2021-08-27'] > train['q_5']
I get Automatic reindexing on DataFrame vs Series comparisons is deprecated and will raise ValueError in a future version. Do left, right = left.align(right, axis=1, copy=False)before e.g.left == right` and something strange output with a lot of columns, but I did expect cell values masked with True or False for calculate sum on next step.
Comparing each columns separately works just fine
train['nd_mean_2021-04-15'] > train['q_5']
But works slowly and messy code.
CodePudding user response:
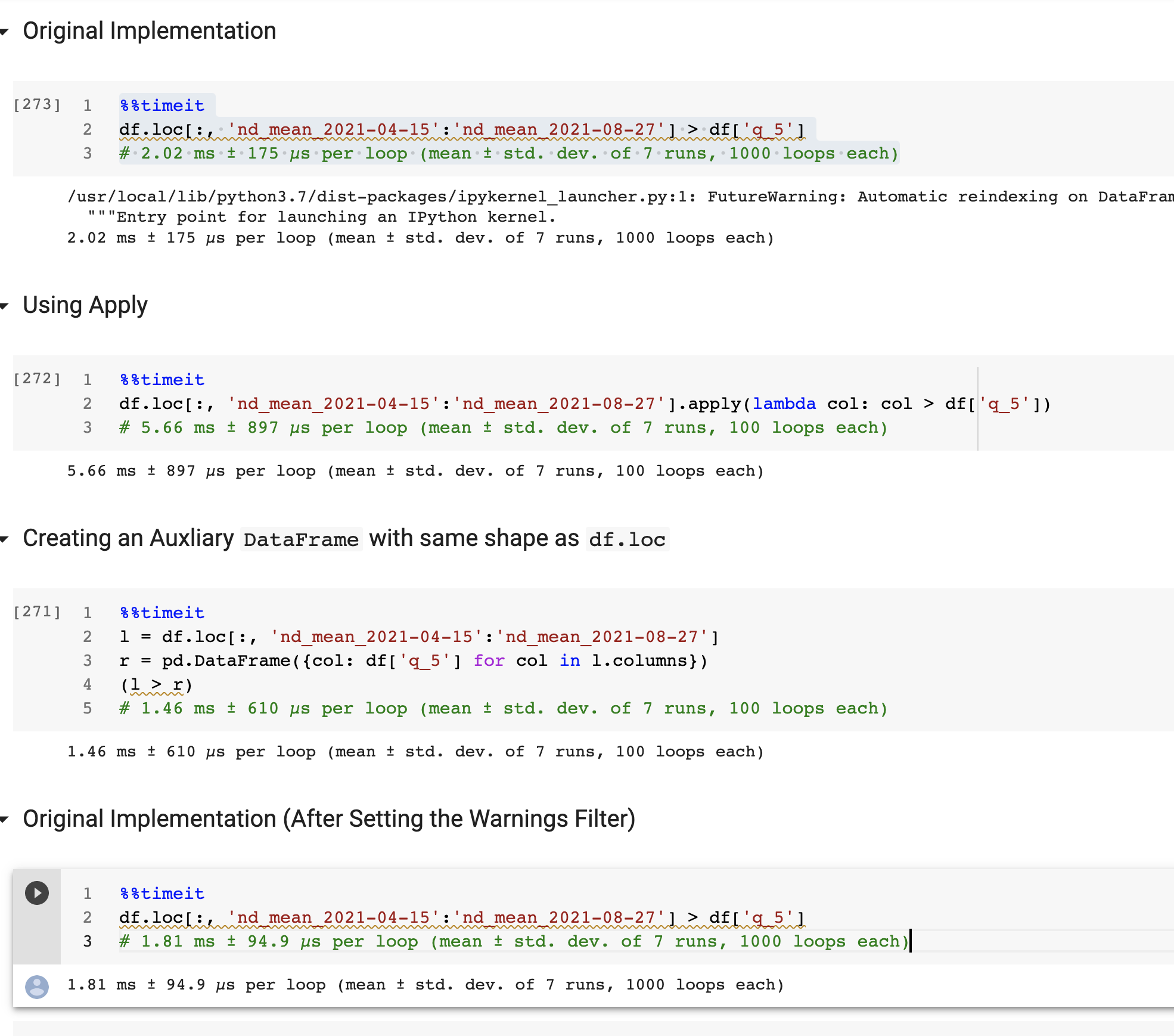
I've tested your original solution, and two additional ways of performing this comparison you want to make.
To cut to the chase, the following option had the smallest execution time:
%%timeit
sliced_df = df.loc[:, 'nd_mean_2021-04-15':'nd_mean_2021-08-27']
comparisson_df = pd.DataFrame({col: df['q_5'] for col in sliced_df.columns})
(sliced_df > comparisson_df)
# 1.46 ms ± 610 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Drawback: it's little bit messy and requires you to create 2 new objects (sliced_df and comparisson_df)
Option 2: Using DataFrame.apply (slower but more readable)
The second option although slower than your original and the above implementations, in my opinion is the cleanest and easiest to read of them all. If you're not trying to process large amounts of data (I assume not, since you're using pandas instead of Dask or Spark that are tools more suitable for processing large volumes of data) then it's worth bringing it to the discussion table:
%%timeit
df.loc[:, 'nd_mean_2021-04-15':'nd_mean_2021-08-27'].apply(lambda col: col > df['q_5'])
# 5.66 ms ± 897 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Original Solution
I've also tested the performance of your original implementation and here's what I got:
%%timeit
df.loc[:, 'nd_mean_2021-04-15':'nd_mean_2021-08-27'] > df['q_5']
# 2.02 ms ± 175 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Side-Note: If the FutureWarning message is bothering you, there's always the option to ignore them, adding the following code after your script imports:
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)
DataFrame Used for Testing
All of the above implementations used the same dataframe, that I created using the following code:
import pandas as pd
import numpy as np
columns = list(
map(
lambda value: f'nd_mean_{value}',
pd.date_range('2021-04-15', '2021-08-27', freq='W').to_series().dt.strftime('%Y-%m-%d').to_list()
)
)
df = pd.DataFrame(
{col: np.random.randint(0, 100, 10) for col in [*columns, 'q_5']}
)
Screenshots