Context: I have a dataframe that I queried using SQl. From this query, I saved to a dataframe using pandas on spark API. Now, after some transformations, I'd like to save this new dataframe on a new table at a given database.
Example:
spark = SparkSession.builder.appName('transformation').getOrCreate()
df_final = spark.sql("SELECT * FROM table")
df_final = ps.DataFrame(df_final)
## Write Frame out as Table
spark_df_final = spark.createDataFrame(df_final)
spark_df_final.write.mode("overwrite").saveAsTable("new_database.new_table")
but this doesn't work. How can I save a pandas on spark API dataframe directly to a new table in a database (this database doesn't exist yet) Thanks
CodePudding user response:
You can use the following procedure. I have the following demo table.
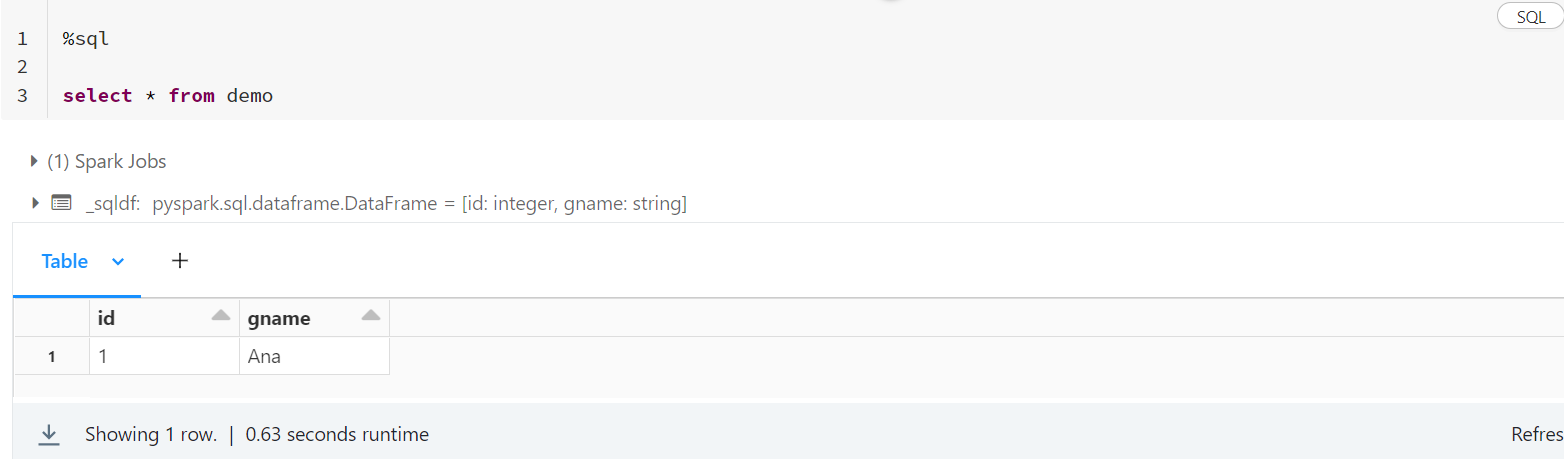
- You can convert it to pandas dataframe of spark API using the following code:
df_final = spark.sql("SELECT * FROM demo")
pdf = df_final.to_pandas_on_spark()
#print(type(pdf))
#<class 'pyspark.pandas.frame.DataFrame'>
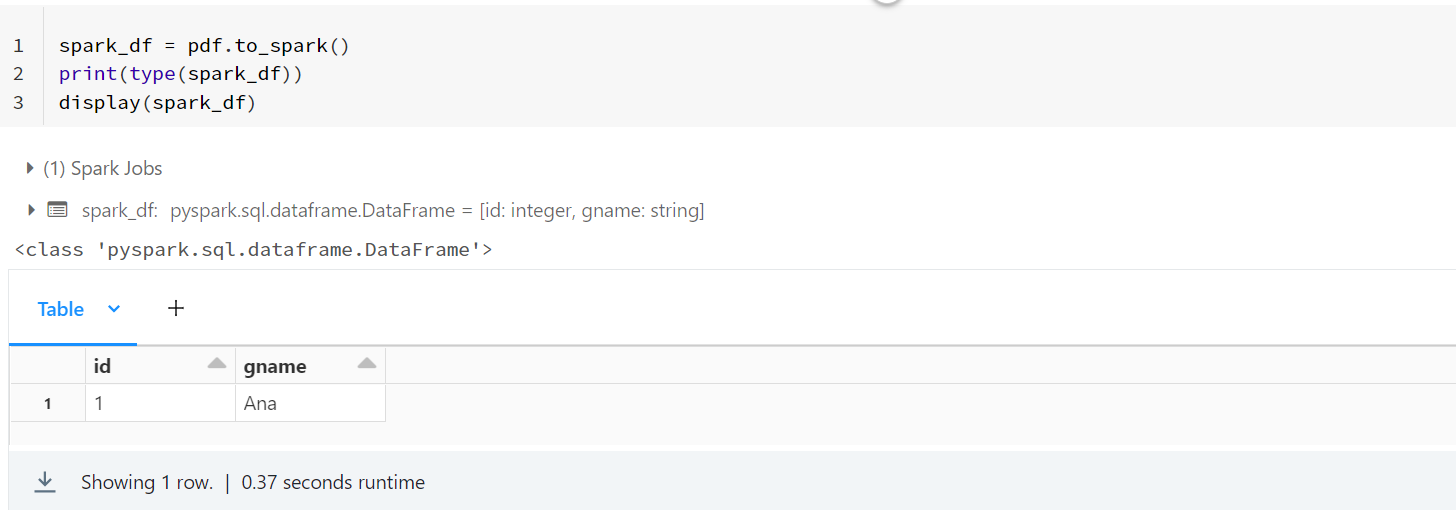
- Now after performing your required operations on this pandas dataframe on spark API, you can convert it back to spark dataframe using the following code:
spark_df = pdf.to_spark()
print(type(spark_df))
display(spark_df)
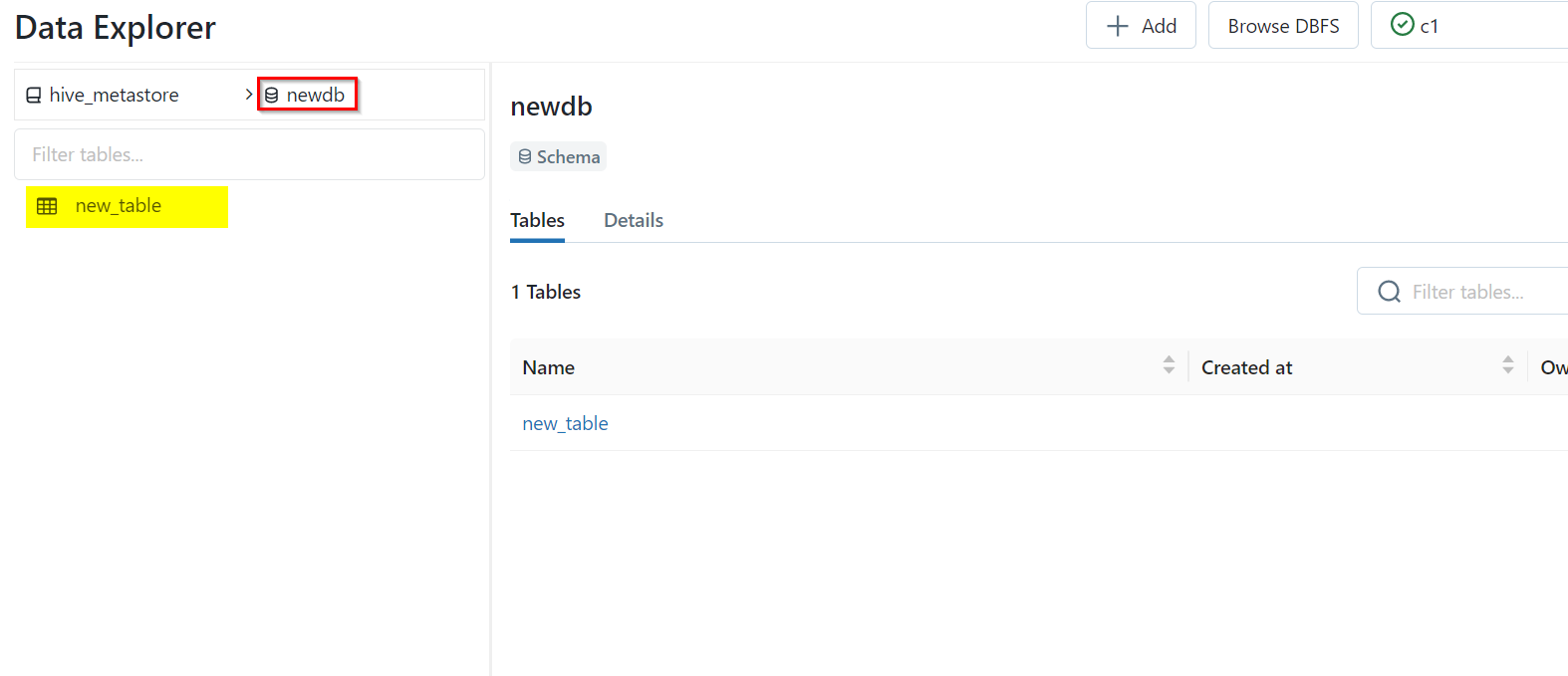
- Now to write this dataframe to a table into a new database, you have to first create the database first and then write the dataframe to table.
spark.sql("create database newdb")
spark_df.write.mode("overwrite").saveAsTable("newdb.new_table")
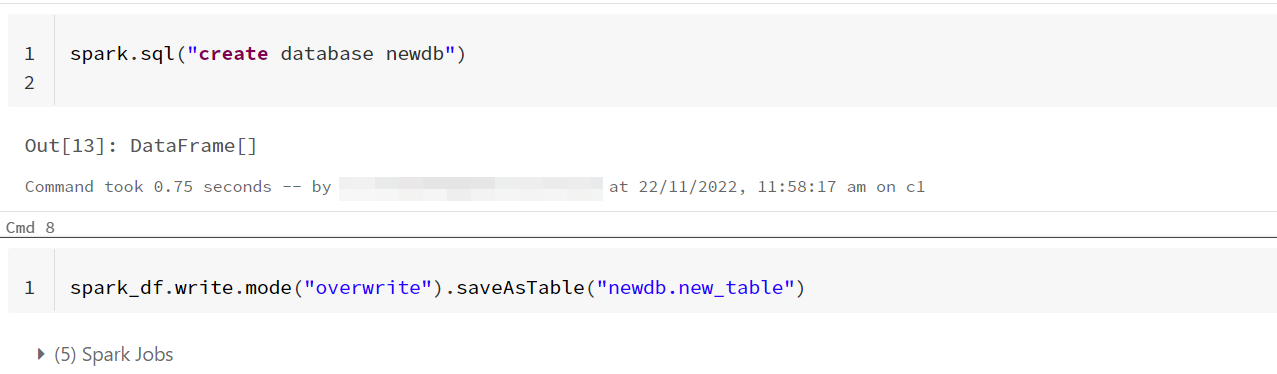
- You can see that the table is written to the new database. The following is a reference image of the same: