I have a set of data that has multiple groups across multiple time points (sample cut below):
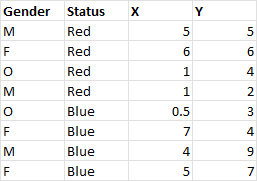
I've been trying to conduct multiple cor.test between X and Y between each status, and across each gender.
I was having a hard time figuring out the group comparison so I filtered by status and split my gender cor.tests separately for Status = Red and Status = Blue (using filter).
This is my current code which runs cor.test across each gender:
red_status <- all %>% filter(status == "Red")
cor_red <- by(red_status, red_status$gender,
FUN = function(df) cor.test(df$X, df$Y, method = "spearman"))
The output result shows the 3 different cor.test across each gender:
red_status$gengrp: M
Spearman's rank correlation rho
data: df$X and df$Y
S = 123.45, p-value = 0.123
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.123456
----------------------------------
red_status$gengrp: F
... (same output style as gengrp: M ^)
----------------------------------
red_status$gengrp: O
... (same output style as gengrp: M ^)
What I'm trying to do is extract the estimate and p-values across all gender cor.test and place them in a dataframe.
I thought I can use the data.frame() function to extract the gender name and correlation elements, then just add another column for p-values, however doing this gave me an error:
# Where red_status[1] is gender names (M,F,O) and red_status[[3:4]] are the Spearman p-value and rho estimate *within each gender category*
data.frame(group = dimnames(red_status)[1], est = as.vector(red_status)[[3]],
pval = as.vector(red_status[[4]])
Error in as.data.frame.default(x[[i]], optional = TRUE, stringsAsFactors = stringsAsFactors) :
cannot coerce class ‘"htest"’ to a data.frame
Since I filtered by Status == Red, I'd have to rerun the codes again to get the result for the gender cor.test results of Status == Blue then at the end bind the estimates and p-values all to 1 df.
My goal is to be able to create a data frame that shows the correlation estimate and p-value across each status and gender:
Status Gender Estimate(rho) P-value
Red M 1.23 0.123
Red F 0.45 0.054
Red O ... ...
Blue M 0.004 0.123
Blue F ... ...
Blue O ... ...
Any help/tips would be appreciated.
CodePudding user response:
Answer based off of @Ruam Pimentel's comment regarding the rstatix package.
Using piping the cor_test() function, I can group by both status and gender to run the correlation test. The cor_test() function is designed to output a dataframe containing all elements of the correlation (i.e. statistic, p-value, estimate) all depending on the correlation method of choice.
This is the code that worked:
r <- dfall %>%
group_by(status, gender) %>%
cor_test(X, Y, method = "spearman")
Result (edited the numbers):
status gengrp var1 var2 cor statistic p method
<chr> <fct> <chr> <chr> <dbl> <dbl> <dbl> <chr>
1 Red M X Y 0.98 -0.123 0.123 Spearman
2 Red F X Y 0.12 0.456 0.456 Spearman
3 Red O X Y 0.34 0.944 0.789 Spearman
4 Blue M X Y 0.56 0.246 0.101 Spearman
5 Blue F X Y 0.78 0.4107 0.111 Spearman
6 Blue O X Y 0.9 0.123 0.122 Spearman
CodePudding user response:
While the rstatix solution will require considerably less code than a Base R solution, I'm posting one to demonstrate that it is possible to create the requested output in Base R.
The key to a Base R solution is understanding how to navigate the output object from cor.test() to extract the requested content, convert it into single row data frames, and rbind() the list of objects into a single data frame.
First, we generate some data.
set.seed(9108171) # for reproducibility
gender <- rep(c("F","M", "O"),40)
status <- c(rep("Red",60),rep("Blue",60))
x <- round(rnorm(120,mean = 6,sd = 2),1)
y <- round(rnorm(120,mean = 8,sd = 1),1)
df <- data.frame(gender,status, x, y)
Next, we filter down to the red items per the code in the original post, and run the cor.test() function.
# filter red
library(dplyr)
red_status <- filter(df,status == "Red")
cor_red <- by(red_status, red_status$gender,
FUN = function(df) cor.test(df$x, df$y, method = "spearman"))
Finally we use lapply() to extract the data and combine it into a data frame. Note the use of the [[ form of the extract operator, which removes one layer of nesting from the list of lists that was generated by cor.test(). Also note how we use a vector of names, the categories of gender, to drive lapply(). These values were used to distinguish the by groups in the previous call to cor.test().
# extract the required data
theResults <- lapply(c("F","M","O"),function(x){
aTest <- cor_red[[x]]
data.frame(status = "Red",
test = names(aTest$statistic),
value = aTest$statistic,
p_value = aTest$p.value,
rho = aTest$estimate)
})
# rbind the results into a single data frame
do.call(rbind,theResults)
...and the results for the Red status:
> do.call(rbind,theResults)
status test value p_value rho
S Red S 1072.672 0.4137465 0.19347947
S1 Red S 1396.400 0.8344303 -0.04992459
S2 Red S 1281.132 0.8777763 0.03674259
We can repeat the procedure for the Blue status and combine the results to obtain the following:
> rbind(blueResults,redResults)
status test value p_value rho
S Blue S 1541.034 0.50402812 -0.15867211
S1 Blue S 1087.954 0.44253280 0.18198950
S2 Blue S 1880.742 0.06950608 -0.41409194
S3 Red S 1072.672 0.41374648 0.19347947
S11 Red S 1396.400 0.83443026 -0.04992459
S21 Red S 1281.132 0.87777629 0.03674259
>
The complete script to produce the final table is:
set.seed(9108171) # for reproducibility
gender <- rep(c("F","M", "O"),40)
status <- c(rep("Red",60),rep("Blue",60))
x <- round(rnorm(120,mean = 6,sd = 2),1)
y <- round(rnorm(120,mean = 8,sd = 1),1)
df <- data.frame(gender,status, x, y)
# filter red
library(dplyr)
red_status <- filter(df,status == "Red")
cor_red <- by(red_status, red_status$gender,
FUN = function(df) cor.test(df$x, df$y, method = "spearman"))
# extract the required data
theResults <- lapply(c("F","M","O"),function(x){
aTest <- cor_red[[x]]
data.frame(status = "Red",
test = names(aTest$statistic),
value = aTest$statistic,
p_value = aTest$p.value,
rho = aTest$estimate)
})
# rbind the results into a single data frame
redResults <- do.call(rbind,theResults)
redResults
blue_status <- filter(df,status == "Blue")
cor_blue<- by(blue_status, blue_status$gender,
FUN = function(df) cor.test(df$x, df$y, method = "spearman"))
# extract the required data
theResults <- lapply(c("F","M","O"),function(x){
aTest <- cor_blue[[x]]
data.frame(status = "Blue",
test = names(aTest$statistic),
value = aTest$statistic,
p_value = aTest$p.value,
rho = aTest$estimate)
})
# rbind the results into a single data frame
blueResults <- do.call(rbind,theResults)
rbind(blueResults,redResults)
I recognize that I could abstract out the repeated code into a support function to reduce the total lines of code needed for the solution, but that's left as a trivial exercise for the reader.