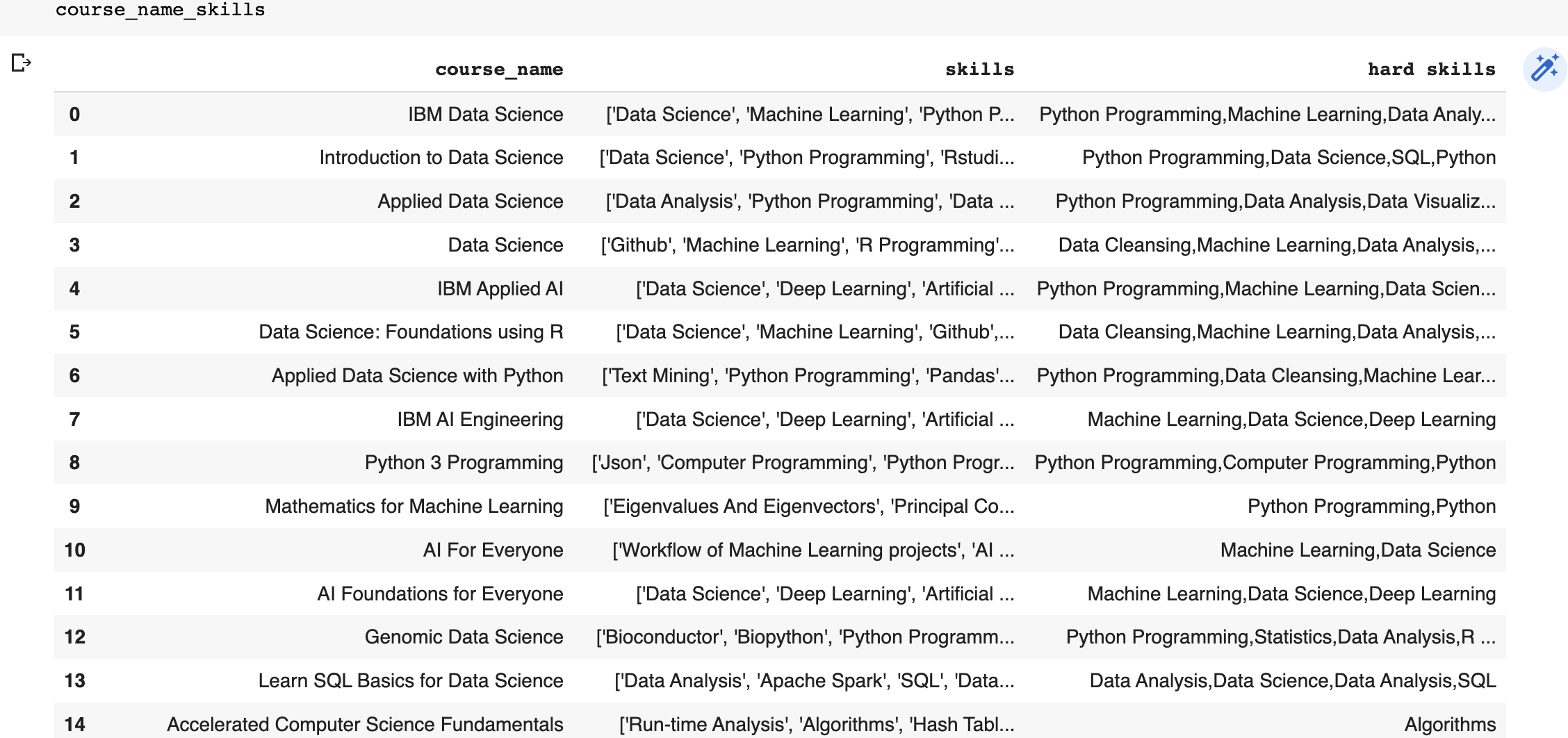
I've extracted key words from a different column to make a new column (hard skills) that looks like this: (https://i.stack.imgur.com/XNOIK.png)
{kind=link}
But I want to make each key word into a list format within the "hards skills" column. For example, for the 1st row of "hard skills" column, my desired outcome would be:
['Python Programming', 'Machine Learning', 'Data Analysis'...]
instead of
Python Programming,Machine Learning,Data Analysis...
This is how I filtered the key words out into the new "hard skills" column.
#Filter and make new column for hard skills hard_skills = ['Python Programming', 'Statistics', 'Statistical Hypothesis Testing','Data Cleansing', 'Tensorflow', 'Machine Learning', 'Data Analysis','Data Visualization', 'Cloud Computing', 'R Programming', 'Data Science','Computer Programming', 'Deep Learning', 'Data Analysis', 'SQL', 'Regression Analysis', 'Algorithms', 'JavaScript', 'Python']
def get_hard_skills(skills): return_hard_skills = "" for hard_skill in hard_skills: if skills.find(hard_skill) >= 0: if return_hard_skills == "": return_hard_skills = hard_skill else: return_hard_skills = return_hard_skills "," hard_skill if return_hard_skills == "": return ('not found') else: return return_hard_skills
course_name_skills['hard skills'] = ""
#loop through data frame to get hard skills
for i in range(0,len(course_name_skills)-1): #every single line of the data science courses skills = course_name_skills.loc[i,"skills"] if not isNaN(skills): #if not empty course_name_skills.loc[i,"hard skills"] = get_hard_skills(skills)
course_name_skills = course_name_skills.replace('not found',np.NaN) only_hardskills = course_name_skills.dropna(subset=['hard skills'])
Is there a way I could change the code that filtered the data frame for key words? Or is there a more efficient way?
I tried strip.() or even tried my luck with
return_hard_skills = "[" return_hard_skills "," hard_skill "]"
But it didn't come through.
[Dataframe with original column]
random, but needed, true or false table generated
{kind=link}
CodePudding user response:
IIUC, there is no need for functions and/or loops here since you can use pandas.Series.str.join to get your expected column/output :
course_name_skills["hard skills"]= course_name_skills["skills"].str.join(",")
NB: The line above assumes that the column hard skills holds lists, otherwise (if strings) use this :
course_name_skills["hard skills"]= (
course_name_skills["skills"]
.str.strip("[]")
.replace({"'": "", "\s ": ""}, regex=True)
)
CodePudding user response:
df['skills'] = df['hard skills'].str.split(',').apply(
lambda skills: [skill.strip() for skill in skills]
)
And if you want to add filtering:
skills = list(set(df['skills'].sum()))
for skill in skills:
df[skill] = df['skills'].apply(lambda x: skill in x)
df.loc[df['Data Analysis']==True]['course_name']