I am trying to import many excel files (around 400) into one dataframe from a folder but I seem to be running into an error.
The files I want from my folder are names filename followed by a date - "filename_yyyy_mm_dd.xlsx".
I want to keep the header as the files have all same columns for different dates.
My current code is:
import glob
import pandas as pd
import os
path = r"C:\Users\..."
my_files = glob.glob(os.path.join(path, "filename*.xlsx"))
file_li = []
for filename in my_files:
df = pd.read_excel(filename, index_col=None, header=1)
file_li.append(df)
frame = pd.concat(file_li, axis=0, ignore_index=True)
When I call my frame I dont get any response? Am I doing something wrong in the way I am calling the file name?
Update:
My excel files look like this:
| Column 1 | Column 2 | Column 3 | Column 4 | Column 5 | Column 6 | Column 7 | Column 8 | Column 9 | Column 10 | Column 11 | Column 12 | Column 13 | Column 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | SREC-MD | SREC | Feb-25 | MDX | F | 85 | 0 | 0 | 8086 | 02/25/2025 | 20107 |
with around 300-400 rows.
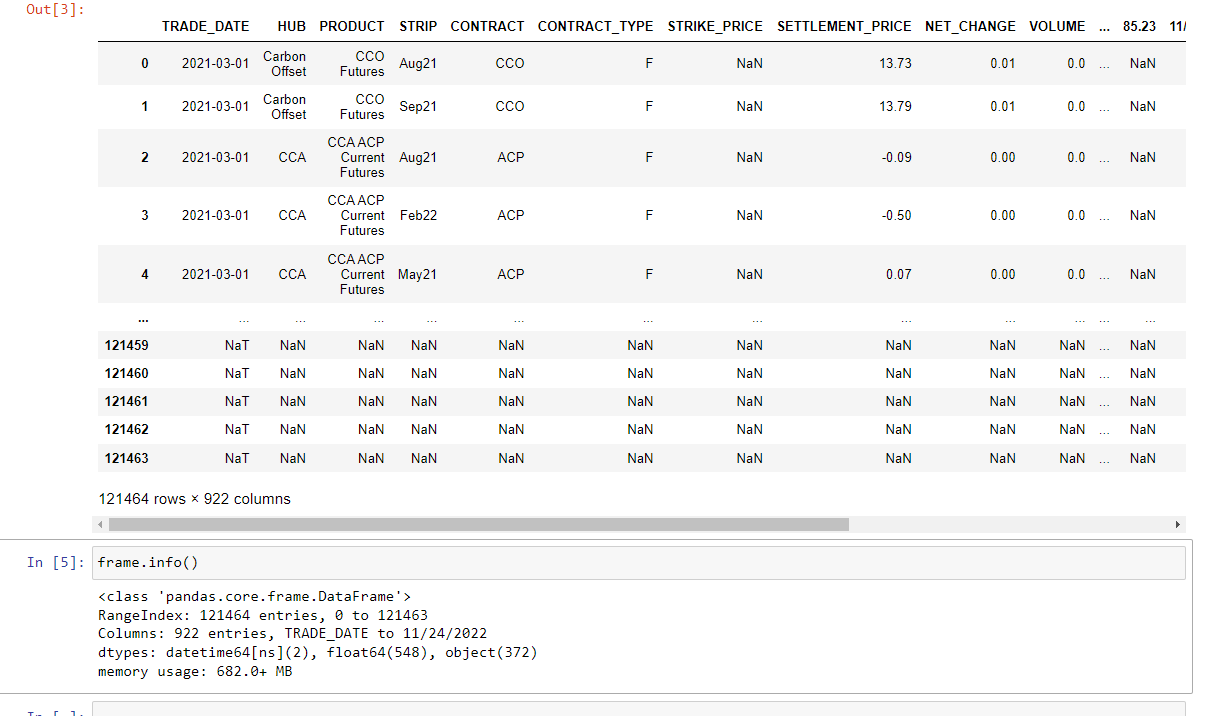
My output has captured the 14 columns but it has added a lot more as doing frame.info() shows I have 922 columns.
Update 2:
CodePudding user response:
It's hard to tell why you're getting the extra columns but you can try this :
import glob
import pandas as pd
import os
path = r"C:\Users\..."
my_files = glob.glob(os.path.join(path, "filename*.xlsx"))
file_li = []
for filename in my_files:
df = pd.read_excel(filename, index_col=None, header=None)
file_li.append(df)
frame = (
pd.concat(file_li, axis=0, ignore_index=True)
.dropna(how="all") #to get rid of the eventual extra rows abobe each header
.drop_duplicates() #to get rid of the cumulated duplicated headers
.T.set_index(0).T #to make the first row as header of the dataframe
)
I suggest you however to check if there is any missing rows in frame compared to your spreadsheets.
CodePudding user response:
Instead of using concat, you could try reading the files into a df and then append them to one combined csv using mode='a'. Then read the combined csv.
for filename in my_files:
df = pd.read_excel(filename, index_col=None, header=1)
df.to_csv('combined.csv', mode='a', header=False)
df = pd.read_csv('combined.csv')