I am extracting data from an html file, it is in a table format so I made this line of code to convert all the tables to a data frame with pandas.
dfs = pd.read_html("synced_contacts.html")
Now, printing the 2nd row of tables of the data frame
dfs[1]
The output is the following:
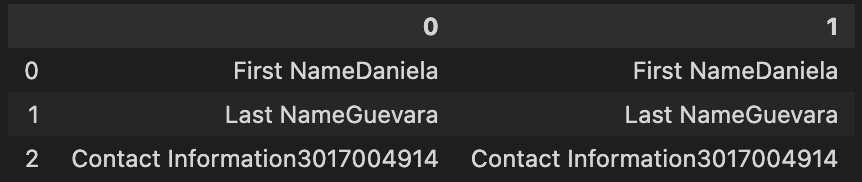
How can I do so that the information is not duplicated in two columns as shown in the image, and also separate "First NameDaniela" in "First Name" as first column and "Daniela" as value
Expected Output:

Table HTML structure:
<title>Synced contacts</title></head><body ><div ><div ><div ><div><table style="width:100%;background:white;position:fixed;z-index:99;"><tr style=""><td height="8" style="line-height:8px;"> </td></tr><tr style="background:white"><td style="text-align:left;height:28px;width:35px;"></td><td style="text-align:left;height:28px;"><img src="files/Instagram-Logo.png" height="28" alt="Instagram" /></td></tr><tr style=""><td height="5" style="line-height:5px;"> </td></tr></table><div style="width:100%;height:44px;"></div></div><div ><div ><div ><div >Synced contacts</div><div >Contacts you've synced</div></div></div><div role="main"><div ><div ><table style="table-layout: fixed;"><tr><td colspan="2" >First Name<div><div>Daniela</div></div></td></tr><tr><td colspan="2" >Last Name<div><div>Guevara</div></div></td></tr><tr><td colspan="2" >Contact Information<div><div>3017004914</div></div></td></tr></table></div><div ></div></div><div ><div ><table style="table-layout: fixed;"><tr><td colspan="2" >First Name<div><div>Marianna</div></div></td></tr><tr><td colspan="2" >Contact Information<div><div>3125761972</div></div></td></tr></table></div><div ></div></div><div ><div ><table style="table-layout: fixed;"><tr><td colspan="2" >First Name<div><div>Ana Maria</div></div></td></tr><tr><td colspan="2" >Last Name<div><div>Garzon</div></div></td></tr><tr><td colspan="2" >Contact Information<div><div>3214948507</div></div></td></tr></table></div>CodePudding user response:
It is caused by the struture, everything is placed in a single <td> and will be concatenated, the colspan is creating the second column.
pd.read_html() is a good for the first and easiest pass, not necessarily that it will handle every messy table in real life.
So instead using the pd.read_html() you could use BeautifulSoup directly to fit the behavior of how to scrape to your needs and create a dataframe from the result. .stripped_strings is used here to split the texts of each element in the <tr> to a list.
pd.DataFrame(
[
dict([list(row.stripped_strings)for row in t.select('tr')])
for t in soup.select('table:has(._2pin)')
]
)
Example
from bs4 import BeautifulSoup
html='''
<title>Synced contacts</title></head><body ><div ><div ><div ><div><table style="width:100%;background:white;position:fixed;z-index:99;"><tr style=""><td height="8" style="line-height:8px;"> </td></tr><tr style="background:white"><td style="text-align:left;height:28px;width:35px;"></td><td style="text-align:left;height:28px;"><img src="files/Instagram-Logo.png" height="28" alt="Instagram" /></td></tr><tr style=""><td height="5" style="line-height:5px;"> </td></tr></table><div style="width:100%;height:44px;"></div></div><div ><div ><div ><div >Synced contacts</div><div >Contacts you've synced</div></div></div><div role="main"><div ><div ><table style="table-layout: fixed;"><tr><td colspan="2" >First Name<div><div>Daniela</div></div></td></tr><tr><td colspan="2" >Last Name<div><div>Guevara</div></div></td></tr><tr><td colspan="2" >Contact Information<div><div>3017004914</div></div></td></tr></table></div><div ></div></div><div ><div ><table style="table-layout: fixed;"><tr><td colspan="2" >First Name<div><div>Marianna</div></div></td></tr><tr><td colspan="2" >Contact Information<div><div>3125761972</div></div></td></tr></table></div><div ></div></div><div ><div ><table style="table-layout: fixed;"><tr><td colspan="2" >First Name<div><div>Ana Maria</div></div></td></tr><tr><td colspan="2" >Last Name<div><div>Garzon</div></div></td></tr><tr><td colspan="2" >Contact Information<div><div>3214948507</div></div></td></tr></table></div>
'''
soup = BeautifulSoup(html)
pd.DataFrame(
[
dict([list(row.stripped_strings)for row in t.select('tr')])
for t in soup.select('table:has(._2pin)')
]
)
Output
| First Name | Last Name | Contact Information | |
|---|---|---|---|
| 0 | Daniela | Guevara | 3017004914 |
| 1 | Marianna | nan | 3125761972 |
| 2 | Ana Maria | Garzon | 3214948507 |