I am new to Azure Data Lakes. Currently I am using ADLS Gen2. I have configured pipelines for single source data sets to destination data sets. This is working fine. Then I configured the pipeline for uploading / ingesting whole database from on-prem to ADLS gen2.
Here is the process: Factory studio -> Ingest -> Built-in copy task -> sql server as Data store and configured runtime -> Select All tables (Existing tables) -> and so on.
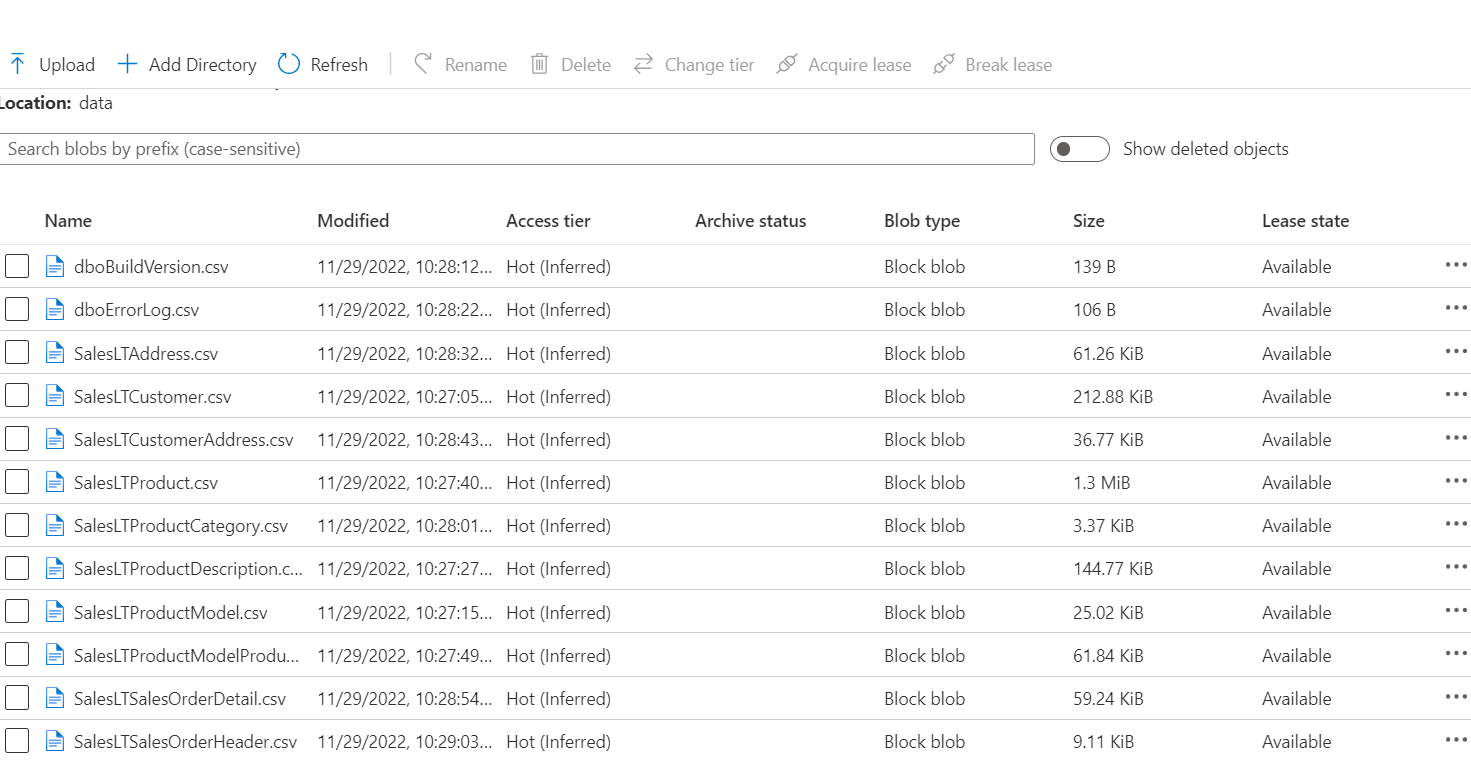
Then from pipelines when I trigger this activity, it successfully uploads all tables to containers in separate files(based on source table names)
Then when I update data in one of the tables in sources it successfully updates the data in destination file.
But the problem is when I add new table in database and then triggers the activity, this new table is not uploaded. Is there a way to update source data set to include this new table?
I have seen all the properties of source data set and activity in pipeline. Also searched for the solution, but stuck in this scenario.
CodePudding user response:
To dynamically get list of all tables and copy it to your datalake storage account, you can use the following procedure:
I have used a script activity on my azure SQL database (for demonstration) to get the list of tables in my database using the following query as suggested by @Scott Mildenberger:
SELECT TABLE_SCHEMA,TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE='BASE TABLE'
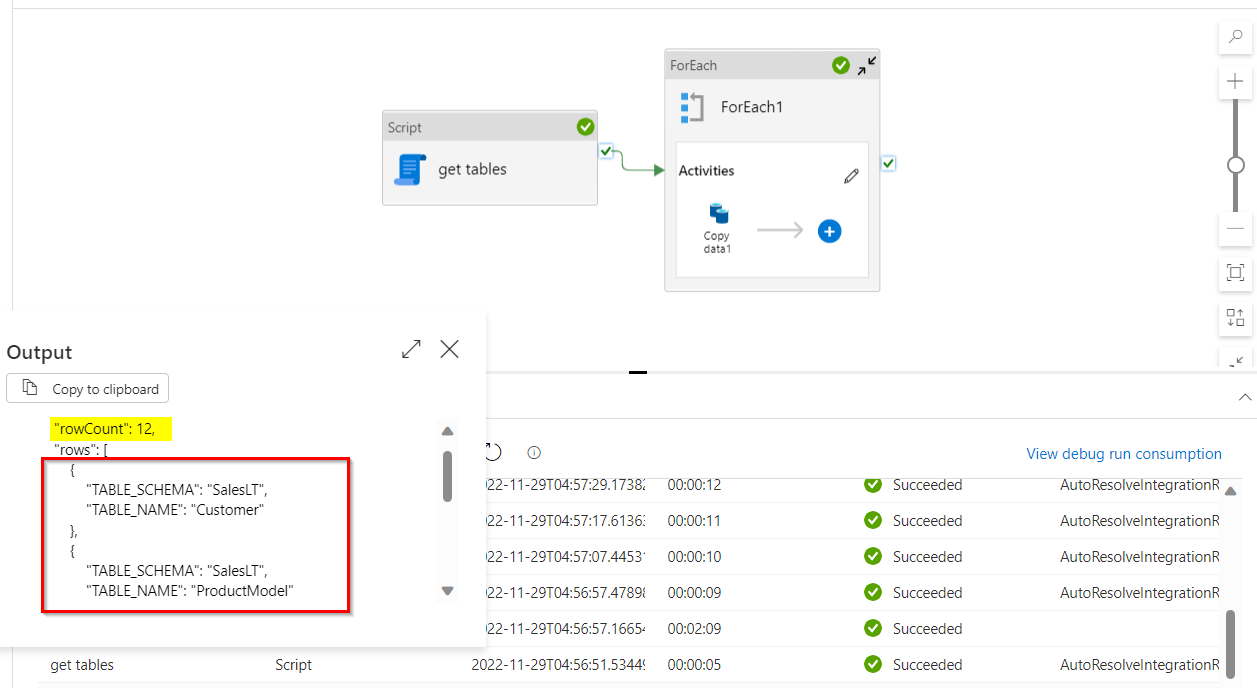
Now in
for eachloop, Use items value as the output rows of above script activity i.e.,@activity('get tables').output.resultSets[0].rows. Inside for each loop, use a copy activity, where source is your database and destination is ADLS sink.I have created 2 parameters for sink destination called
schemaandtableand used them as shown below:
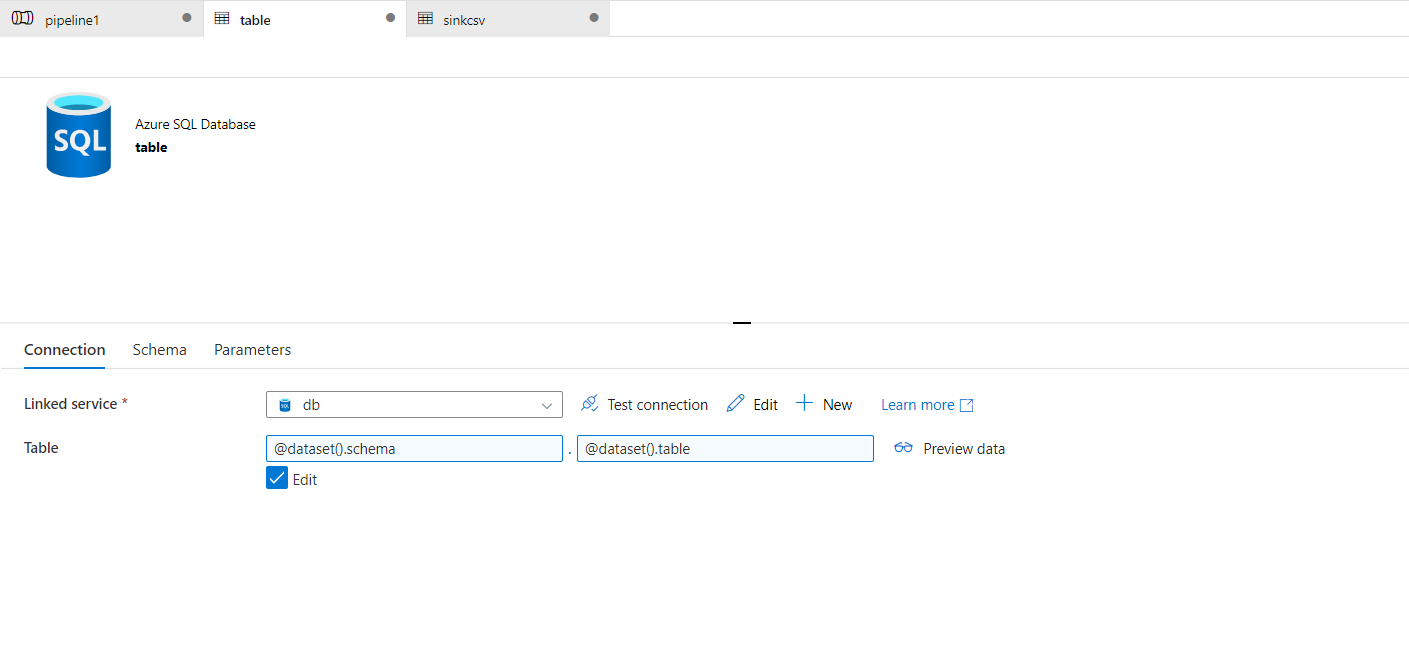
- In the source settings of copy activity, I have given the values for these dataset parameters as following:
schema: @item().TABLE_SCHEMA
table: @item().TABLE_NAME
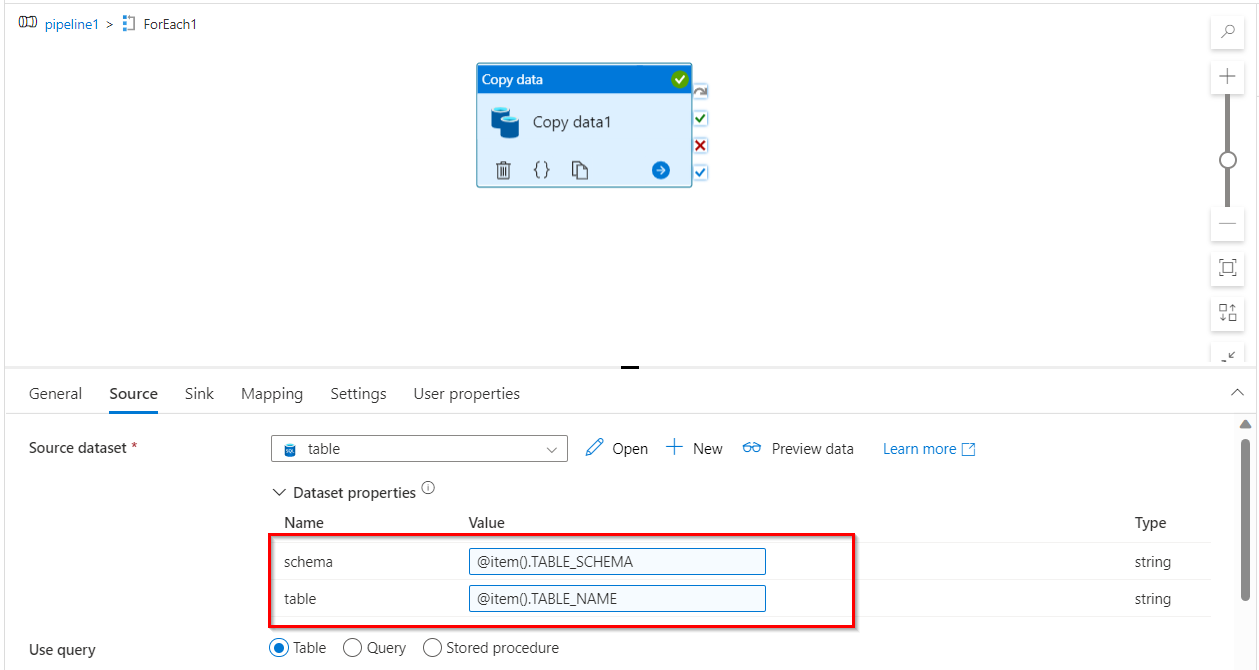
- For ADLS sink, I have created 2 parameters called
schemaandtableand I have used it to create file name dynamically as@{dataset().schema}@{dataset().table}.csv.
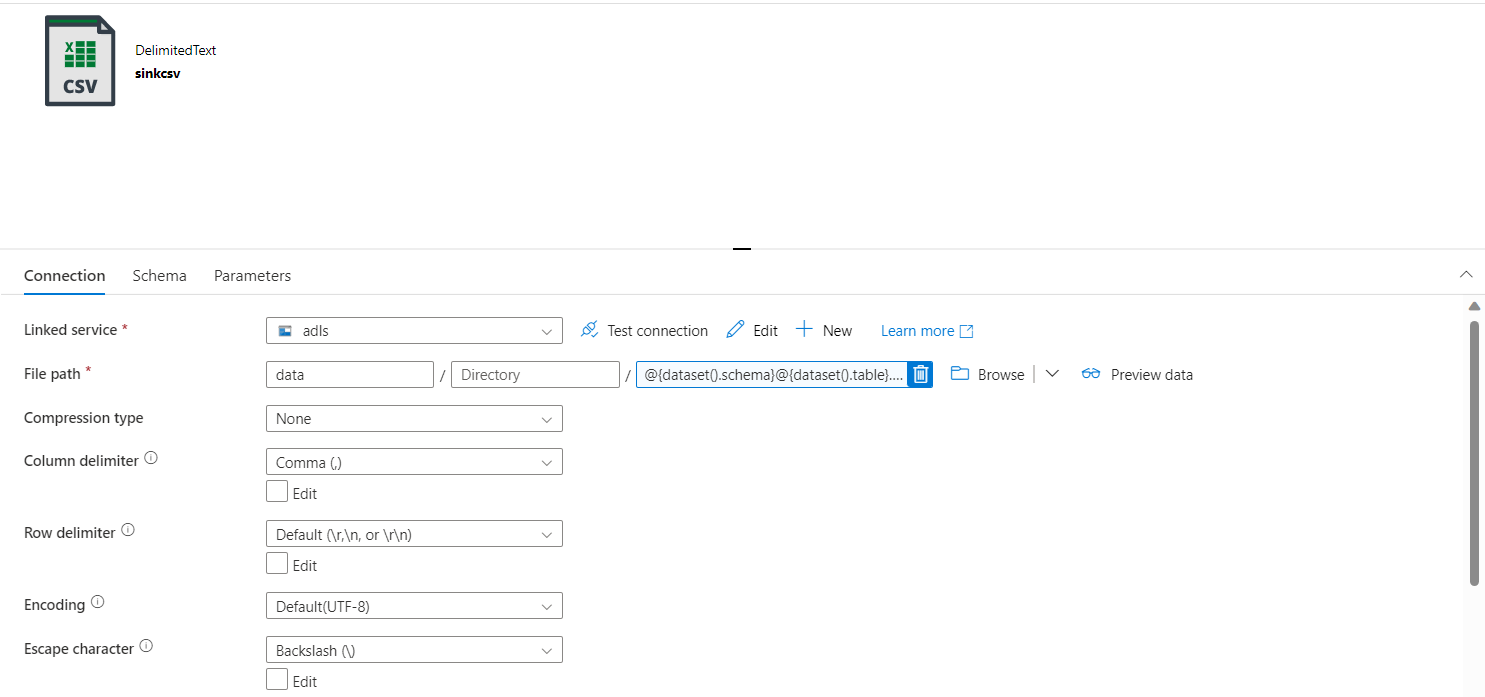
- I have given its values in sink settings of copy data same as above.
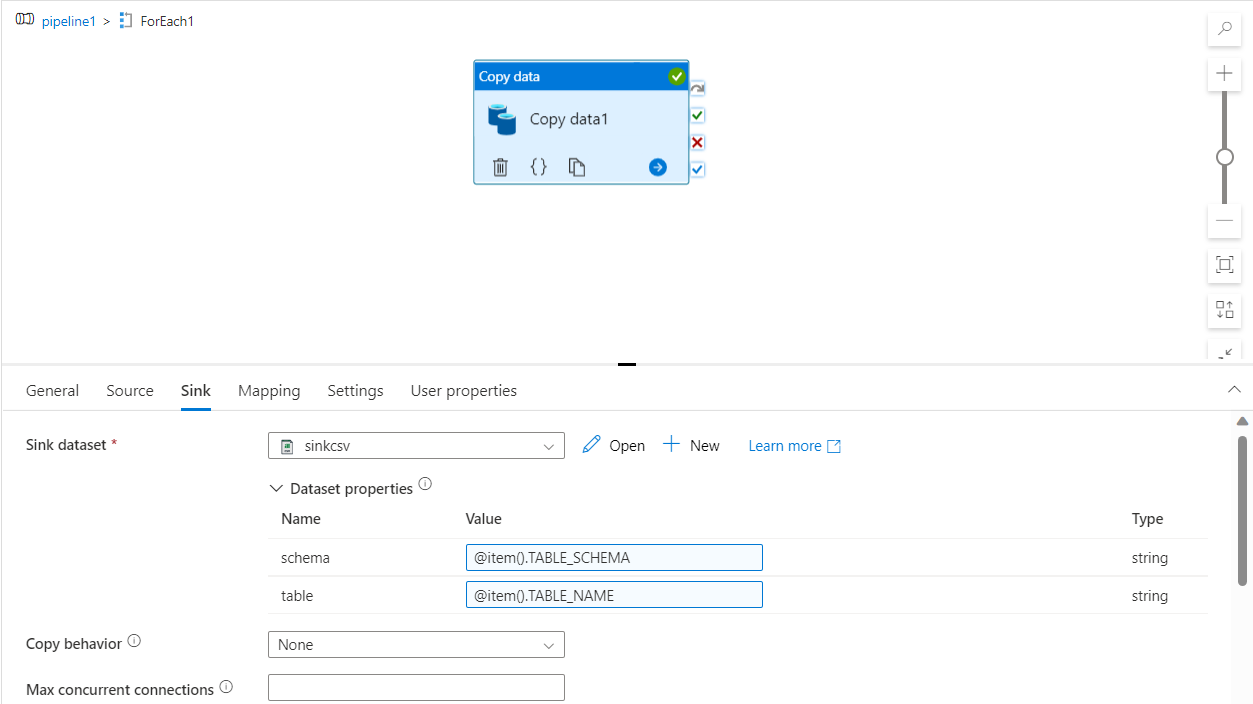
- When I run the pipeline, it will give desired results. The following is a reference image. Even when you add a new table, the query will pick this up and copy it as a file to your ADLS container.