I am using spark2.4.5 with java8 in my spark job which writes data into an s3 path. Due to multiple triggers of job accidentally, it created duplicate records. I am trying to remove the duplicates from s3 path using databricks.
While i am trying to perform delete operation as below from table "final_vals"
%sql
delete from final_vals where rank1 in (select rank1 from ( select ROW_NUMBER() over ( partition by id,data_date,data_type,data_value, version_id order by create_date,last_update_date ) as rank1
from final_vals )
where rank1 <> 1 ) ;
Its throwing error as below
Error in SQL statement: DeltaAnalysisException: Multi-column In predicates are not supported in the DELETE condition.
How to fix this issue? what am I doing wrong here?
CodePudding user response:
I tried to reproduce your scenario and getting similar error

The error might be causing because of the Delete in databricks while using predicates some limitations are there like:
The following types of subqueries are not supported:
- Nested subqueries, that is, an subquery inside another subquery
NOT INsubquery inside anOR, for example,a = 3 OR b NOT IN (SELECT c from t)
The work around is
Create dataframe with your query from which you are trying to get rank1 column
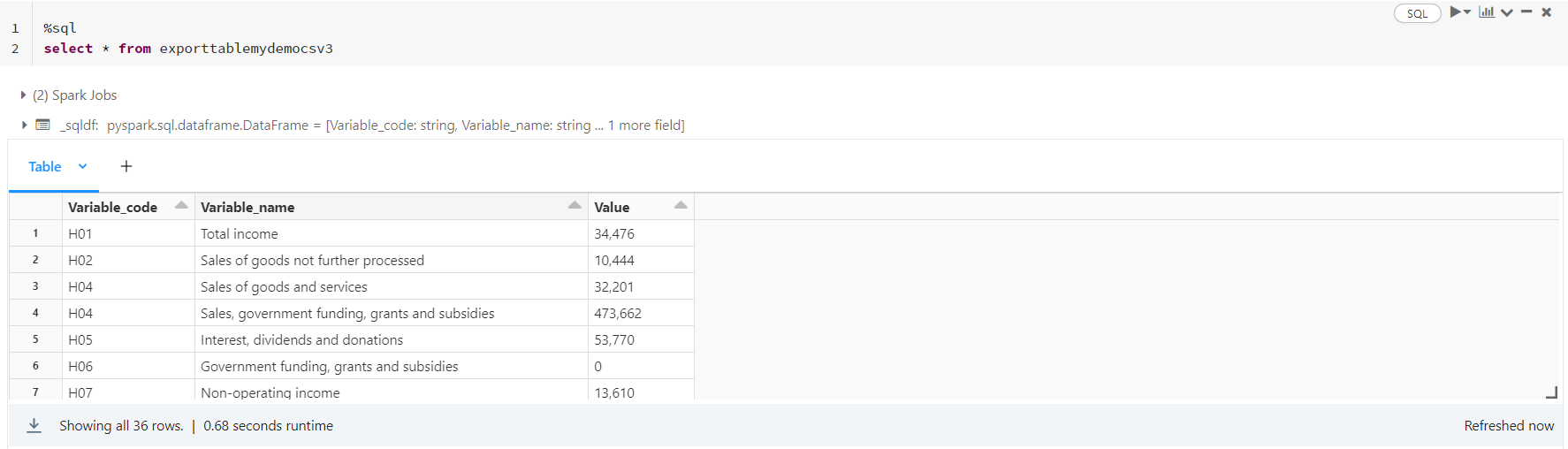
df2 = spark.sql("select *,ROW_NUMBER() over (partition by Variable_code,Variable_name order by Value ) as rank1 from exporttablemydemocsv")
df2.show()
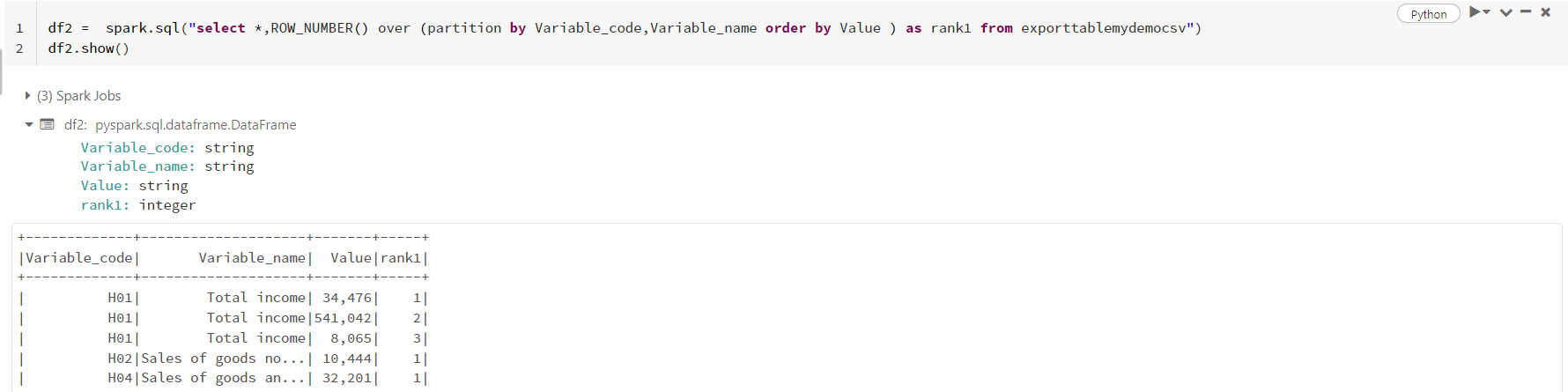
Then create another table with data frame and after that delete the rows where rank1 is not equal to 1 and delete that column.
df2.write.format("delta").mode("overwrite").saveAsTable("exporttablemydemocsv3")
%sql
delete from exporttablemydemocsv3 where rank1!=1;
%sql
ALTER TABLE exporttablemydemocsv3 DROP COLUMN rank1
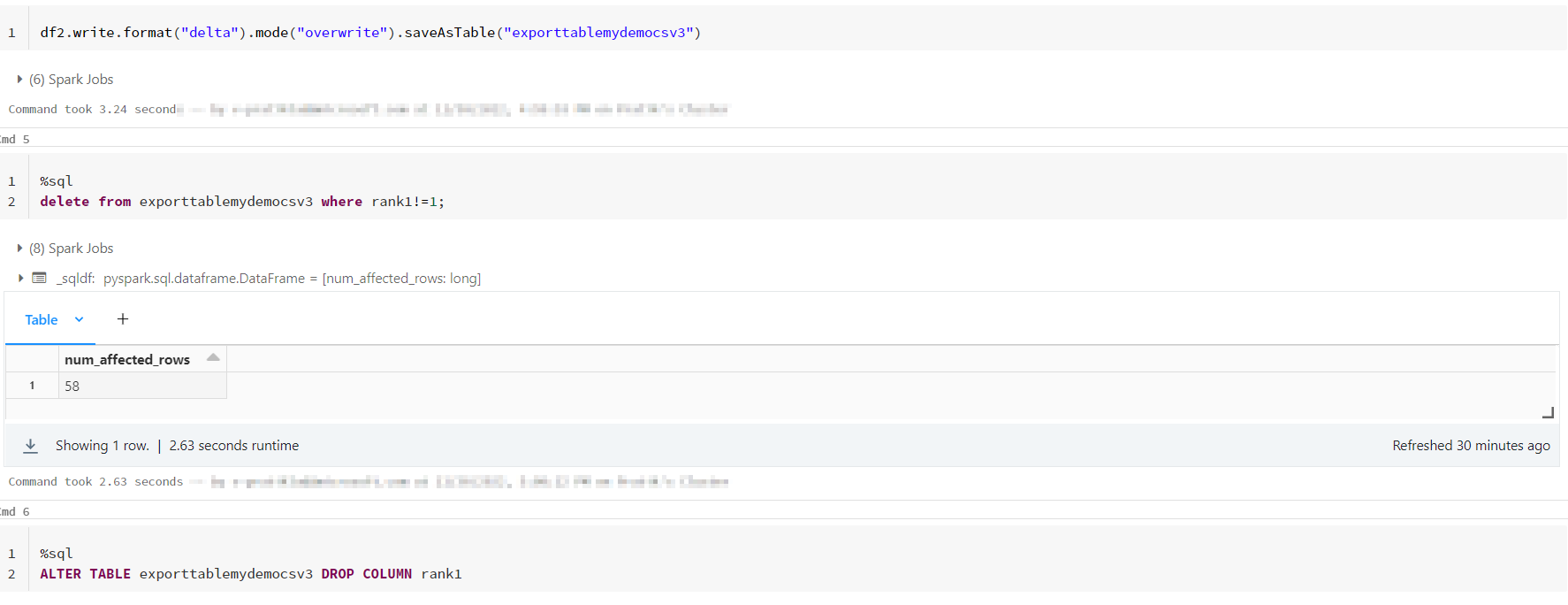
Output