I have a pandas Dataframe named df and it has a column named logvalues. I want to create a new column, violatedInstances based on these log values.
If Max >= logvalue >= Min assign 0 (Not violated) If logvalue > Max or logvalue < Min assign 1 (Violated)
#create DataFrame
df_x = pd.DataFrame({'logvalue': ['20', '20.5', '18.5', '2', '10'],
'ID': ['1', '2', '3', '4', '5']})
Max = 20
min = 15
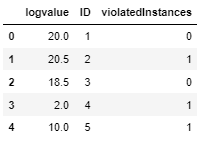
Output should look like below.
| logvalue | ID | violatedInstances |
|---|---|---|
| 20 | 1 | 0 |
| 20.5 | 2 | 1 |
| 18.5 | 3 | 0 |
| 2 | 4 | 1 |
| 10 | 5 | 1 |
Sorry for asking this simple question. I tried several methods but nothing worked. How can I do this in pandas?
CodePudding user response:
Your logvalue type is string so you'll have to convert to float:
df_x['violatedInstances'] = df_x['logvalue'].astype(float).apply(lambda x: 1 if (x > Max or x < Min) else 0)
CodePudding user response:
cond1 = pd.to_numeric(df_x['logvalue']).gt(20)
cond2 = pd.to_numeric(df_x['logvalue']).lt(15)
df_x.assign(violatedInstances= (cond1 | cond2).astype('int'))
result:
logvalue ID violatedInstances
0 20 1 0
1 20.5 2 1
2 18.5 3 0
3 2 4 1
4 10 5 1
CodePudding user response:
First I would convert logvalue to a float so you can perform comparisons
df_x['logvalue'] = df_x['logvalue'].astype('float')
Then you can use numpy as such:
import numpy as np
df_x['violatedInstances'] = np.where(((df_x['logvalue'] > Max) | (df_x['logvalue'] < Min)), 1, 0)
which outputs: